搜索 Instagram 和 TikTok 上的用户账户 涉及从这些平台收集数据。需要注意的是,在这些平台上搜索可能会违反其服务条款,并可能导致账户封禁或法律后果。因此,使用 代理 旋转 IP 地址是网络搜索的必备技巧。有鉴于此,以下是从 Instagram/TikTok 网页界面提取用户数据的分步指南!
如何用 Python 在 IG 和 TikTok 上抓取用户账户
让我们来看看如何从 Instagram 和 TikTok 抓取用户配置文件数据,包括用户名、全名、描述和配置文件图片。

步骤 1:设置环境
- 安装 Python 和 Pip: 确保计算机上安装了 Python。您可以从 python.org.Pip 是 Python 的软件包安装程序,通常随 Python 一起安装。
- 安装所需的库:
pip install requests beautifulsoup4 pandas selenium - 下载 Webdriver: 对于 Selenium,您需要为浏览器下载相应的 WebDriver。对于 Chrome 浏览器,您可以从以下地址获取 ChromeDriver 这里.
第 2 步:为 Instagram 创建扫描器
A.搜索公共数据
基本设置:
导入请求
from bs4 import BeautifulSoup
将 pandas 导入 pd
# 获取 HTML 内容的函数
def get_html(url):
response = requests.get(url)
返回 response.text提取用户信息:
def scrape_instagram_user(username):
url = f'https://www.instagram.com/{username}/'
html = get_html(url)
soup = BeautifulSoup(html, 'html.parser')
# 提取相关数据
user_data = {}
user_data['username'] = 用户名
user_data['full_name'] = soup.find('meta', {'property': 'og:title'})['content'].split('-')[0].strip()
user_data['description'] = soup.find('meta', {'property': 'og:description'})['content'].
user_data['profile_image'] = soup.find('meta', {'property': 'og:image'})['content']
返回 user_data
# 使用示例
user = scrape_instagram_user('instagram')
print(user)B.使用 Selenium 处理动态内容
设置 Selenium:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
导入时间
# 设置 WebDriver
chrome_options = Options()
chrome_options.add_argument("--headless")
service = ChromeService(executable_path='/path/to/chromedriver')
driver = webdriver.Chrome(service=service, options=chrome_options)
# 获取动态内容的函数
def get_dynamic_content(url):
driver.get(url)
time.sleep(3) # 等待页面加载
return driver.page_source
# 示例用法
html = get_dynamic_content('https://www.instagram.com/instagram/')第 3 步:为 TikTok 创建扫描器
A.搜索公共数据
基本设置:
def scrape_tiktok_user(username):
url = f'https://www.tiktok.com/@{username}'
html = get_html(url)
soup = BeautifulSoup(html, 'html.parser')
# 提取相关数据
user_data = {}
user_data['username'] = 用户名
user_data['full_name'] = soup.find('h1', {'data-e2e': 'user-title'}).text if soup.find('h1', {'data-e2e': 'user-title'}) else None
user_data['description'] = soup.find('h2', {'data-e2e': 'user-subtitle'}).text if soup.find('h2', {'data-e2e': 'user-subtitle'}) else None
user_data['profile_image'] = soup.find('img', {'class': 'avatar'})['src'] if soup.find('img', {'class': 'avatar'}) else None
返回 user_data
# 使用示例
user = scrape_tiktok_user('tiktok')
print(user)B.使用 Selenium 处理动态内容
设置 Selenium:
# 重用 Instagram 部分的 Selenium 设置
# TikTok 的使用示例
html = get_dynamic_content('https://www.tiktok.com/@tiktok')第 4 步:将数据保存为 CSV
保存数据:
def save_to_csv(data, filename='output.csv'):
df = pd.DataFrame(data)
df.to_csv(filename, index=False)
# 示例用法
data = [scrape_instagram_user('instagram'), scrape_tiktok_user('tiktok')] 保存_to_csv(data)。
save_to_csv(data)步骤 5:使用代理和处理速率限制
使用代理搜索 Instagram 和 TikTok,如 OkeyProxy是一种网络搜刮代理,对于规避费率限制和 IP 禁止 这些代理由平台规定,旨在防止过度提取数据并维护其服务的完整性。通过代理,您可以在多个 IP 地址上分配您的搜索请求,从而降低被标记为可疑用户的可能性,并确保您能持续访问所需的数据。这一点在 TikTok 等平台上尤为重要,因为在这些平台上,高请求量可能会触发自动防御,阻止或限制访问。通过利用代理,您可以保持稳定高效的刮擦操作,在收集数据时不会面临重大中断。
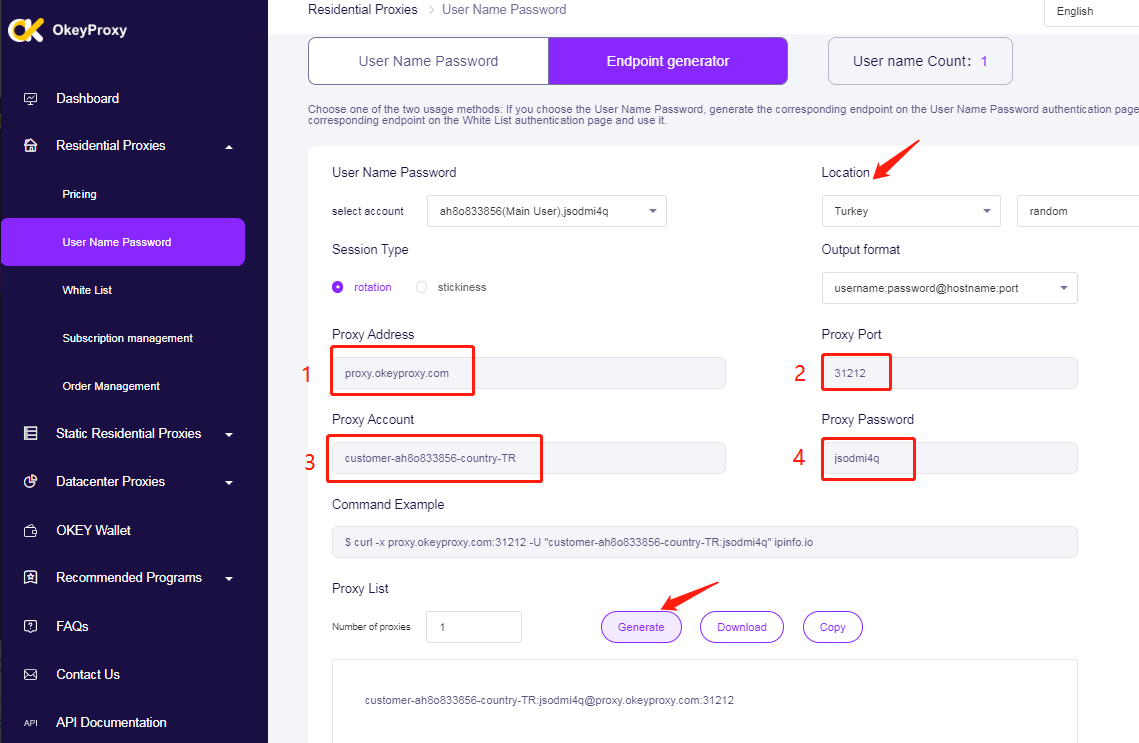
设置代理:
代理服务器 = {
'http':http://your_proxy_here'、
https': 'https://your_proxy_here'、
}
# 请求使用示例
response = requests.get(url, proxies=proxies)处理速率限制:
导入时间
# 添加延迟的函数
def delayed_request(url, delay=2):
time.sleep(delay)
return get_html(url)在 Instagram 和 TikTok 上抓取数据的案例研究示例
场景
您的任务是收集一些 Instagram 和 TikTok 用户的个人资料数据,分析他们在社交媒体上的表现,以便开展营销活动。
步骤
- 设置环境: 确保安装了所有必需的库,并设置了 WebDriver。
- 抓取 Instagram 用户数据:
instagram_usernames = [ 'instagram'、'cristiano'、'natgeo'] instagram_data = [] for username in instagram_usernames: user_data = scrape_instagram_user(username) instagram_data.append(user_data) save_to_csv(instagram_data, 'instagram_users.csv') - 抓取 TikTok 用户数据:
tiktok_usernames = ['tiktok', 'charlidamelio', 'therock'] tiktok_usernames = ['tiktok', 'charlidamelio', 'therock']. tiktok_data = [] for username in tiktok_usernames: user_data = scrape_tiktok_user(username) tiktok_data.append(user_data) save_to_csv(tiktok_data, 'tiktok_users.csv') - 使用 Selenium 处理动态内容: 使用 Selenium 设置检索页面源并解析数据,以获取具有动态内容的配置文件。
其他方法使用 API 从 Instagram/Tiktok 抓取用户账户
使用 Instagram API
Instagram 提供的 API 可以访问公共数据。不过,这种 API 有一定的局限性,而且需要审批,因此对于大规模的数据搜刮来说灵活性较差。
- 在 Facebook for Developers 上注册开发者账户。
- 创建 Instagram 基本显示应用程序。
- 使用 API 端点访问用户数据,包括用户配置文件和媒体。

使用 TikTok API
TikTok 提供了一个公共应用程序接口,用于访问一些用户数据,但与 Instagram 一样,该应用程序接口也有限制,并且需要批准。
- 通过开发者门户网站申请 TikTok API 访问权。
- 使用 API 端点收集用户配置文件和内容。

在 Instagram/Tiktok 上抓取用户账户的注意事项
- 确保您有权抓取数据,并遵守平台的服务条款。
- 适当延迟和使用 代理 以避免受阻。
- 负责任地处理刮擦数据,尊重用户隐私。
摘要
就是这样。按照这些步骤通过 Python 与代理或平台的原始 API 提取数据,你就可以有效地在 Instagram 和 TikTok 上搜刮用户账户,同时遵守法律和道德准则。