
数据是竞争分析、市场研究和业务战略的基石。对于电子商务企业来说,全球最大的在线市场亚马逊是最有价值的数据来源之一。在亚马逊上搜索卖家的产品,可以深入了解定价策略、产品供应和客户评价,这对做出明智的商业决策至关重要。
本文深入探讨了在亚马逊上搜索卖家产品的过程,涵盖了基本工具、技术和最佳实践,同时涉及法律和道德方面的考虑。
亚马逊的数据结构包括?
亚马逊网站的结构对产品、评论、定价和其他细节进行了分类。要有效地抓取产品数据,了解以下组成部分至关重要:
- 产品列表:包含产品名称、描述、价格和图片等详细信息。
- 卖家信息:包括卖家评级、产品数量和卖家名称。
- 评论和评级:提供客户反馈和产品评级。
- 产品分类:帮助过滤和组织产品。
在亚马逊上搜刮卖家产品的步骤
在亚马逊上抓取卖家的产品需要详细而有条理的方法,特别是由于亚马逊复杂的反抓取措施。以下是一份全面的教程,涵盖了从环境设置到应对验证码和动态内容等挑战的各个方面。
1.准备网络抓取
在进入刮擦流程之前,请确保您的环境已设置好必要的工具和库。
a.工具和图书馆
- Python: 因其丰富的图书馆生态系统而备受青睐。
- 图书馆
要求:用于发出 HTTP 请求。美丽汤:用于解析 HTML 内容。硒:用于处理动态内容和交互。大熊猫:用于数据处理和存储。废料:如果您更喜欢可扩展性更强、基于蜘蛛的刮擦方法。
- 代理管理:
请求-IP-旋转器:用于旋转 IP 地址的库。- 代理服务,如
OkeyProxy用于旋转代理。
- 验证码解码器
- 服务,如
2Captcha或反验证码用于解决验证码问题。
- 服务,如
b.环境设置
- 安装 Python (如果尚未安装)。
- 建立虚拟环境:
python3 -m venv amazon-scraper source amazon-scraper/bin/activate - 安装必要的库:
pip install requests beautifulsoup4 selenium pandas scrapy
2.了解亚马逊的反抢注机制
亚马逊采用了各种技术来防止自动搜刮,这对数据收集来说是个挑战:
- 速率限制: 亚马逊会限制您在短时间内提出申请的次数。
- IP 屏蔽: 来自单一 IP 的频繁请求可能导致临时或永久封禁。
- 验证码 这些信息用于验证用户是否为人类。
- 基于 JavaScript 的内容 有些内容是使用 JavaScript 动态加载的,需要进行特殊处理。
3.查找卖方产品
a.确定卖方 ID
要抓取特定卖家的产品,首先需要确定卖家的唯一 ID 或其店面 URL。URL 通常采用以下格式:
https://www.amazon.com/s?me=SELLER_ID您可以通过访问亚马逊上的卖家店面找到此 URL。
b.获取产品列表
有了卖家的 ID 或 URL,您就可以开始获取产品列表了。由于亚马逊的页面通常是分页的,因此您需要处理分页,以确保所有产品都能被搜刮到。
导入请求
从 bs4 导入 BeautifulSoup
seller_url = "https://www.amazon.com/s?me=SELLER_ID"
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
def get_products(seller_url):
产品 = []
while seller_url:
response = requests.get(seller_url, headers=headers)
soup = BeautifulSoup(response.content, "html.parser")
# 提取产品详细信息
for product in soup.select(".s-title-instructions-style"):
title = product.get_text(strip=True)
products.append(title)
# 查找下一页 URL
next_page = soup.select_one("li.a-last a")
seller_url = f "https://www.amazon.com{next_page['href']}" if next_page else None
返回产品
products = get_products(seller_url)
print(products)4.处理分页
亚马逊产品页面通常是分页的,需要循环浏览每个页面。其逻辑包含在 获取产品 在该函数中,它会检查是否存在 "下一步 "按钮,并提取后续页面的 URL。
5.处理动态内容
某些产品详细信息(如价格或可用性)可能会使用 JavaScript 动态加载。在这种情况下,您需要使用 硒 或 无头浏览器 喜欢 编剧 来呈现页面。
将 Selenium 用于动态内容
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
# 设置 Chrome 浏览器选项
chrome_options = Options()
chrome_options.add_argument("--headless") # 以无头模式运行
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
# 启动 Chrome 浏览器驱动程序
service = Service('/path/to/chromedriver')
driver = webdriver.Chrome(service=service, options=chrome_options)
# 打开卖家页面
driver.get("https://www.amazon.com/s?me=SELLER_ID")
# 等待页面完全加载
driver.implicitly_wait(5)
# 使用 BeautifulSoup 解析页面源代码
soup = BeautifulSoup(driver.page_source, "html.parser")
# 提取产品详细信息
for product in soup.select(".s-title-instructions-style"):
title = product.get_text(strip=True)
print(title)
driver.quit()6.处理验证码
亚马逊可能会使用验证码来阻止刮擦尝试。如果遇到验证码,您需要手动解决,或使用以下服务 2Captcha 以实现流程自动化。
使用 2Captcha 的示例
进口请求
captcha_solution = solve_captcha("captcha_image_url") # 使用类似 2Captcha 的验证码解决服务
# 与您的请求一起提交解决方案
数据 = {
field-keywords': 'your_search_term'、
验证码': 验证码解决方案
}
response = requests.post("https://www.amazon.com/s", data=data, headers=headers)7.代理管理
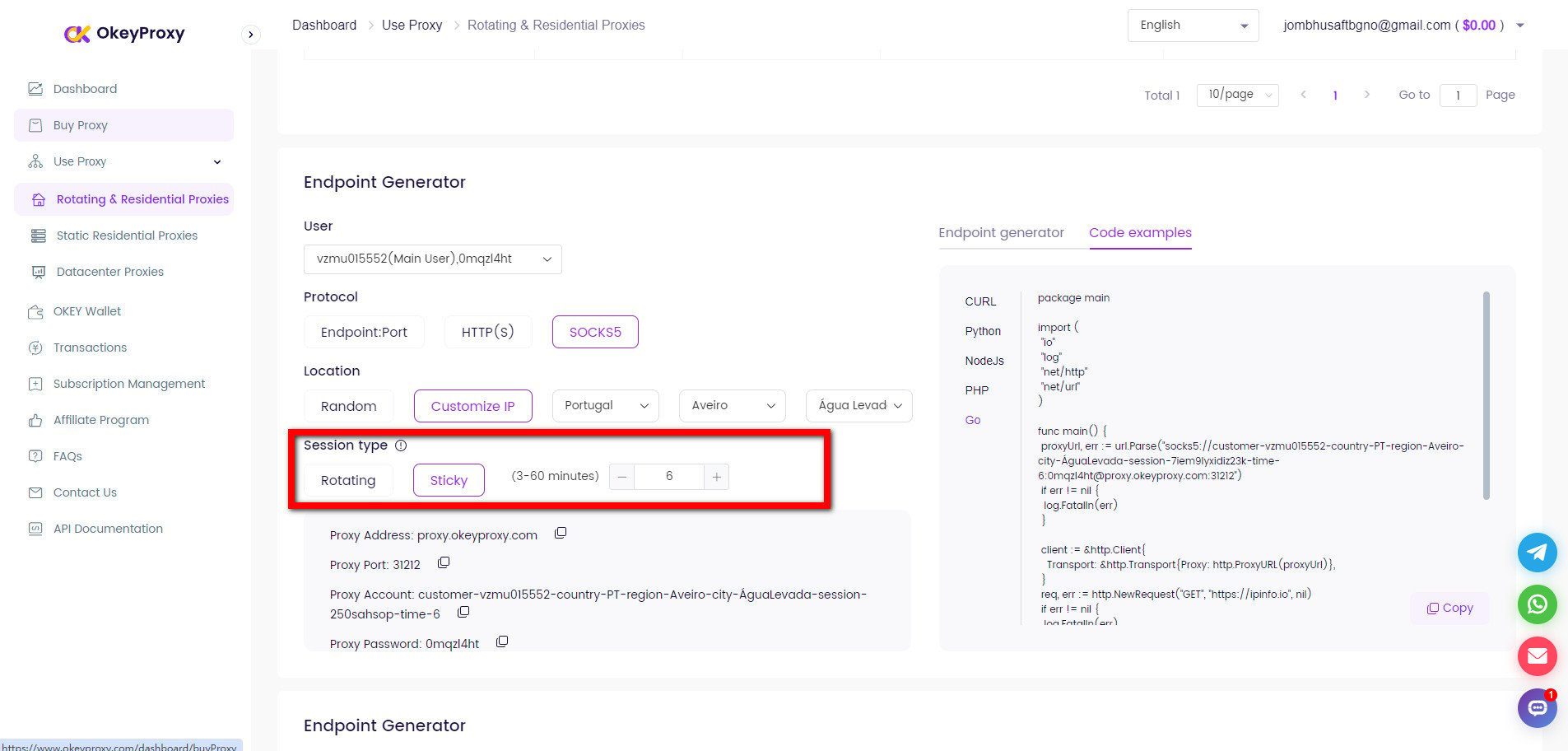
Scraping a seller’s products on Amazon is a common use case for proxies, especially for businesses engaged in price intelligence, competitor monitoring, or product research. Since Amazon employs strong anti-bot measures, proxies for data scraping are essential to bypass detection from Amazon.
为避免 IP 屏蔽,使用轮换代理至关重要。这可以通过代理管理工具或服务来实现。
使用请求设置代理
代理服务器 = {
"http":"http://username:password@proxy_server:port"、
"https":"https://username:password@proxy_server:port"、
}
response = requests.get(seller_url, headers=headers, proxies=proxies)使用 OkeyProxy 旋转 IP 地址
OkeyProxy 是一家拥有专利技术的理想代理服务提供商,提供 1.5 亿多个真实、合规的旋转住宅 IP,可快速连接到任何国家/地区的目标网站,轻松绕过对 IP 的封锁和禁止。
8.数据存储
一旦成功获取数据,请将其存储为结构化格式。 大熊猫 就是一个很好的工具。
用 Pandas 将数据保存为 CSV
import pandas as pd
# 假设产品是一个字典列表
df = pd.DataFrame(products)
df.to_csv("amazon_products.csv", index=False)9.最佳做法和挑战
- 尊重 robots.txt: 始终遵守亚马逊的
robots.txt锉刀 - 速率限制: 实施速率限制策略,防止亚马逊服务器超载。
- 错误处理: 做好处理各种错误的准备,包括请求超时、验证码和页面未找到错误。
- 测试: 在规模运行之前,要在受控环境中对刮刀进行彻底测试。
- 合法性: 确保您的搜刮活动符合法律规定和亚马逊的服务条款。
10.扩展扫描过程
对于大规模刮擦操作,可考虑使用类似于 废料 或在具有分布式抓取功能的云平台上部署刮板。
搜索亚马逊卖家产品的其他方法
亚马逊提供的 API(如产品广告 API)可用于访问产品信息。虽然这种方法是合法的,并得到亚马逊的支持,但它需要 API 访问许可,而且范围有限。
-
优点
官方支持,值得信赖。
-
缺点
访问受限,需要批准,可能涉及使用费用。
FAQs about Scraping Data from Amazon
问题 1:从亚马逊搜索产品数据合法吗?
答:未经许可抓取亚马逊的内容可能违反其服务条款,并可能导致法律后果或 IP 地址被封。请在使用前咨询法律顾问。
问题 2:如何避免在搜索亚马逊时被屏蔽?
答:使用代理服务器轮换 IP、尊重 robots.txt、在请求之间实施延迟、避免过于频繁地进行搜刮等,这些措施可以最大限度地降低被亚马逊屏蔽的风险。
问题 3: 为什么我的刮擦脚本停止工作了?
答:核实亚马逊是否更改了网站结构或实施了新的反搜索措施,并调整脚本以适应任何更改。此外,还要定期检查和维护脚本,以确保其持续功能。
摘要
在亚马逊上抓取卖家的产品包括识别卖家的唯一 URL、浏览分页产品列表以及使用 Selenium 等工具处理动态内容。由于亚马逊采取了验证码和速度限制等反抓取措施,因此必须使用 旋转代理 并考虑遵守其服务条款。对静态内容使用 BeautifulSoup 等库,对动态内容使用 Selenium 等库,再加上对 IP 地址和速率限制的谨慎管理,可以帮助高效地提取和存储产品数据,同时最大限度地降低被拦截的风险。









