
Данные - это краеугольный камень конкурентного анализа, исследования рынка и бизнес-стратегии. Одним из самых ценных источников данных для предприятий электронной коммерции является Amazon, крупнейший в мире онлайн-рынок. Анализ товаров продавца на Amazon может дать представление о ценовой стратегии, ассортименте и отзывах покупателей, что очень важно для принятия обоснованных бизнес-решений.
В этой статье мы подробно рассмотрим процесс соскабливания товаров продавца на Amazon, основные инструменты, методы и лучшие практики, а также юридические и этические аспекты.
Структура данных Amazon включает в себя?
Сайт Amazon структурирован таким образом, что на нем представлены категории товаров, отзывы, цены и другие детали. Для эффективного поиска данных о товарах важно понимать следующие компоненты:
- Объявления о товарах: Содержит такие сведения, как название продукта, описание, цена и изображения.
- Информация о продавце: Включает рейтинг продавца, количество товаров и имя продавца.
- Отзывы и рейтинги: Предоставляет отзывы покупателей и рейтинги товаров.
- Категории продуктов: Помогает фильтровать и упорядочивать продукты.
Пошаговое соскабливание товаров продавца на Amazon
Скраппинг товаров продавца на Amazon требует детального и структурированного подхода, особенно из-за сложных мер Amazon по защите от скраппинга. Ниже представлено полное руководство, охватывающее различные аспекты процесса, от настройки среды до решения таких проблем, как CAPTCHA и динамический контент.
1. Подготовка к веб-скрапингу
Прежде чем приступить к процессу скраппинга, убедитесь, что в вашей среде установлены необходимые инструменты и библиотеки.
a. Инструменты и библиотеки
- Питон: Предпочитается за богатую экосистему библиотек.
- Библиотеки:
запросы: Для выполнения HTTP-запросов.BeautifulSoup: Для разбора содержимого HTML.Селен: Для работы с динамическим контентом и взаимодействиями.Панды: Для манипулирования и хранения данных.Scrapy: Если вы предпочитаете более масштабируемый, основанный на пауках подход к скраппингу.
- Управление доверенностями:
requests-ip-rotator: Библиотека для ротации IP-адресов.- Прокси-сервисы, такие как
OkeyProxyдля вращающихся прокси.
- CAPTCHA Solvers:
- Такие услуги, как
2CaptchaилиАнтикапчадля решения CAPTCHA.
- Такие услуги, как
b. Настройка среды
- Установите Python (если он еще не установлен).
- Создайте виртуальную среду:
python3 -m venv amazon-scraper источник amazon-scraper/bin/activate - Установите необходимые библиотеки:
pip install requests beautifulsoup4 selenium pandas scrapy
2. Понимание механизмов Amazon по борьбе с крапингом
Amazon применяет различные методы для предотвращения автоматического соскабливания, что создает проблемы при сборе данных:
- Ограничение скорости: Amazon ограничивает количество запросов, которые вы можете сделать за короткий промежуток времени.
- Блокировка IP-адресов: Частые запросы с одного IP могут привести к временному или постоянному запрету.
- CAPTCHA: Они представляются, чтобы проверить, является ли пользователь человеком.
- Контент на основе JavaScript: Некоторые материалы загружаются динамически с помощью JavaScript, что требует особой обработки.
3. Нахождение товаров продавца
a. Определите идентификатор продавца
Чтобы получить информацию о товарах конкретного продавца, сначала нужно определить уникальный идентификатор продавца или URL-адрес его витрины. URL обычно имеет следующий формат:
https://www.amazon.com/s?me=SELLER_IDВы можете найти этот URL-адрес, посетив витрину магазина продавца на Amazon.
b. Получение списков продуктов
Получив идентификатор или URL-адрес продавца, вы можете приступить к поиску списков товаров. Поскольку страницы Amazon часто бывают постраничными, вам нужно будет обработать пагинацию, чтобы гарантировать, что все товары будут извлечены.
импортировать запросы
из bs4 import BeautifulSoup
seller_url = "https://www.amazon.com/s?me=SELLER_ID"
заголовки = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
def get_products(seller_url):
products = []
while seller_url:
response = requests.get(seller_url, headers=headers)
soup = BeautifulSoup(response.content, "html.parser")
# Извлечение подробной информации о продукте
for product in soup.select(".s-title-instructions-style"):
title = product.get_text(strip=True)
products.append(title)
# Найдите URL следующей страницы
next_page = soup.select_one("li.a-last a")
seller_url = f "https://www.amazon.com{next_page['href']}" if next_page else None
вернуть товары
products = get_products(seller_url)
print(products)4. Работа с пагинацией
Страницы товаров Amazon часто бывают постраничными, что требует выполнения цикла для перехода по каждой странице. Логика для этого включена в получить_продукты Функция выше, где она проверяет наличие кнопки "Далее" и извлекает URL для последующей страницы.
5. Работа с динамическим содержимым
Некоторые сведения о товаре, например цена или наличие, могут загружаться динамически с помощью JavaScript. В таких случаях необходимо использовать Селен или безголовый браузер например, Драматург для рендеринга страницы перед скраппингом.
Использование Selenium для работы с динамическим контентом
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
# Настройка параметров Chrome
chrome_options = Options()
chrome_options.add_argument("--headless") # Запуск в режиме без головы
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
# Запуск драйвера Chrome
service = Service('/path/to/chromedriver')
driver = webdriver.Chrome(service=service, options=chrome_options)
# Откройте страницу продавца
driver.get("https://www.amazon.com/s?me=SELLER_ID")
# Подождите, пока страница полностью загрузится
driver.implicitly_wait(5)
# Разберите источник страницы с помощью BeautifulSoup
soup = BeautifulSoup(driver.page_source, "html.parser")
# Извлечение сведений о продукте
for product in soup.select(".s-title-instructions-style"):
title = product.get_text(strip=True)
print(title)
driver.quit()6. Работа с CAPTCHA
Amazon может использовать CAPTCHA для блокировки попыток скраппинга. Если вы столкнетесь с CAPTCHA, вам придется либо решить ее вручную, либо воспользоваться таким сервисом, как 2Captcha чтобы автоматизировать процесс.
Пример использования 2Captcha
запросы на импорт
captcha_solution = solve_captcha("captcha_image_url") # Используйте сервис для решения CAPTCHA, например 2Captcha
# Отправьте решение вместе с запросом
данные = {
'field-keywords': 'your_search_term',
'captcha': captcha_solution
}
response = requests.post("https://www.amazon.com/s", data=data, headers=headers)7. Управление доверенностями
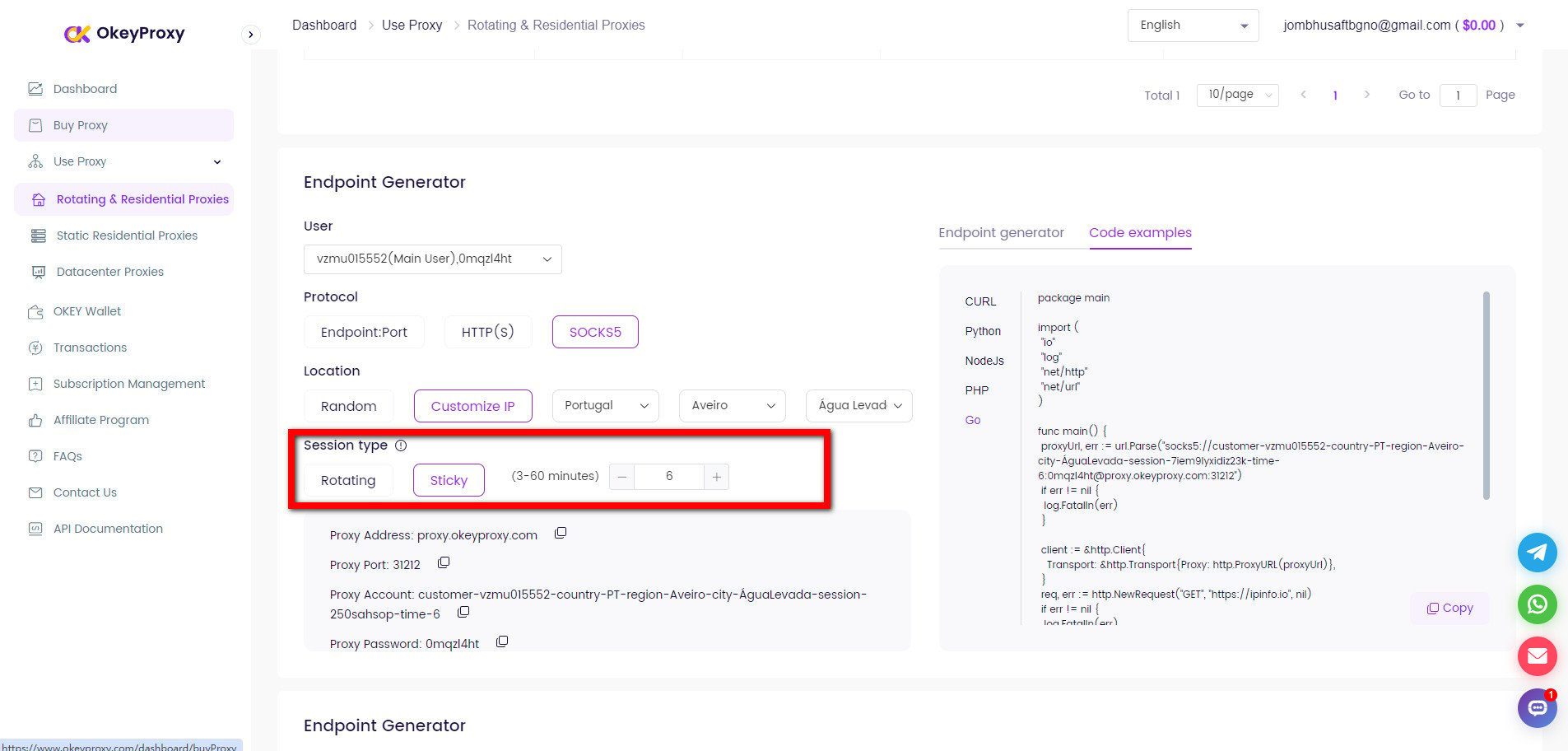
Scraping a seller’s products on Amazon is a common use case for proxies, especially for businesses engaged in price intelligence, competitor monitoring, or product research. Since Amazon employs strong anti-bot measures, proxies for data scraping are essential to bypass detection from Amazon.
Чтобы избежать блокировки IP-адресов, очень важно использовать вращающиеся прокси. Этого можно добиться с помощью инструмента или службы управления прокси.
Настройка прокси с помощью запросов
прокси = {
"http": "http://username:password@proxy_server:port",
"https": "https://username:password@proxy_server:port",
}
response = requests.get(seller_url, headers=headers, proxies=proxies)Ротация IP-адресов с помощью OkeyProxy
OkeyProxy идеальный прокси-провайдер, поддерживаемый запатентованной технологией, которая предоставляет 150 миллионов с лишним реальных и совместимых вращающихся жилых IP-адресов, позволяющих быстро подключаться к целевым веб-сайтам в любой стране/регионе и легко обходить блокировки и запреты IP-адресов.
8. Хранение данных
После того как вы успешно собрали данные, сохраните их в структурированном формате. Панды является отличным инструментом для этого.
Сохранение в CSV с помощью Pandas
import pandas as pd
# Предполагается, что products - это список словарей
df = pd.DataFrame(products)
df.to_csv("amazon_products.csv", index=False)9. Лучшие практики и проблемы
- С уважением robots.txt: Всегда придерживайтесь рекомендаций, указанных в Amazon's
robots.txtфайл. - Ограничение скорости: Реализуйте стратегии ограничения скорости для предотвращения перегрузки серверов Amazon.
- Обработка ошибок: Будьте готовы к обработке различных ошибок, включая таймауты запросов, CAPTCHA и ошибки "страница не найдена".
- Тестирование: Прежде чем запускать скребок в масштабе, тщательно протестируйте его в контролируемых условиях.
- Легальность: Убедитесь, что ваша деятельность по скрапбукингу соответствует законодательным нормам и условиям обслуживания Amazon.
10. Масштабирование процесса скрапирования
Для масштабных операций по скрапбукингу рассмотрите возможность использования таких фреймворков, как Scrapy или развертывание вашего скрепера на облачной платформе с распределенными возможностями сбора информации.
Другой метод поиска товаров продавцов Amazon
Amazon предоставляет такие API, как Product Advertising API, для доступа к информации о товарах. Хотя этот метод является законным и поддерживается Amazon, он требует разрешения на доступ к API и имеет ограниченную сферу применения.
-
Плюсы:
Официальная поддержка, надежность.
-
Конс:
Ограниченный доступ, требуется разрешение и может потребоваться оплата за использование.
FAQs about Scraping Data from Amazon
Вопрос 1: Законно ли искать данные о товарах на Amazon?
О: Использование Amazon без разрешения может нарушить условия предоставления услуг и повлечь за собой юридические последствия или блокировку IP-адресов. Прежде чем приступать к работе, обязательно проконсультируйтесь с юристом.
Вопрос 2: Как избежать блокировки при работе с Amazon?
О: Использование прокси-серверов для ротации IP-адресов, соблюдение robots.txt, задержки между запросами, избегание слишком частого скраппинга и т. д. - вот некоторые меры, которые могут минимизировать риск блокировки со стороны Amazon.
Q3: Почему мой скрипт скраппинга перестал работать?
О: Проверьте, не изменилась ли у Amazon структура сайта или не были ли введены новые меры по борьбе с крапингом, и скорректируйте скрипт с учетом всех изменений. Кроме того, регулярно проверяйте и поддерживайте скрипт, чтобы обеспечить его постоянную функциональность.
Резюме
Скраппинг товаров продавца на Amazon включает в себя определение уникального URL-адреса продавца, навигацию по пагинальным спискам товаров и работу с динамическим контентом с помощью таких инструментов, как Selenium. В связи с тем, что Amazon применяет меры по борьбе со скрапингом, такие как CAPTCHA и ограничение скорости, необходимо использовать вращающиеся прокси и соблюдайте условия предоставления услуг. Использование таких библиотек, как BeautifulSoup для статического контента и Selenium для динамического контента, а также тщательное управление IP-адресами и ограничениями скорости, поможет эффективно извлекать и хранить данные о продукте, сводя к минимуму риск блокировки.








