Скраппинг аккаунтов пользователей в Instagram и TikTok предполагает сбор данных с этих платформ. Важно отметить, что сбор данных с этих платформ может нарушить условия предоставления услуг и привести к запрету аккаунта или юридическим последствиям. Поэтому используйте Прокси-сервер для ротации IP-адреса - необходимый совет для веб-скрапинга. Итак, вот пошаговое руководство по извлечению пользовательских данных из веб-интерфейса Instagram/TikTok!
Как с помощью Python вычислить учетные записи пользователей на IG и TikTok
Давайте рассмотрим, как соскрести данные профиля пользователя из Instagram и TikTok, включая имя пользователя, полное имя, описание и изображение профиля.

Шаг 1: Настройка среды
- Установите Python и Pip: Убедитесь, что на вашей машине установлен Python. Вы можете загрузить его с сайта python.org. Pip, программа установки пакетов для Python, обычно поставляется вместе с установкой Python.
- Установите необходимые библиотеки:
pip install requests beautifulsoup4 pandas selenium - Скачать Webdriver: Для Selenium вам нужно будет загрузить соответствующий WebDriver для вашего браузера. Для Chrome вы можете получить ChromeDriver с сайта здесь.
Шаг 2: Создайте скребок для Instagram
A. Поиск общедоступных данных
Базовая настройка:
импортировать запросы
from bs4 import BeautifulSoup
import pandas as pd
Функция # для получения HTML-контента
def get_html(url):
response = requests.get(url)
return response.textИзвлечение информации о пользователе:
def scrape_instagram_user(username):
url = f'https://www.instagram.com/{username}/'
html = get_html(url)
soup = BeautifulSoup(html, 'html.parser')
# Извлечение релевантных данных
user_data = {}
user_data['username'] = username
user_data['full_name'] = soup.find('meta', {'property': 'og:title'})['content'].split('-')[0].strip()
user_data['description'] = soup.find('meta', {'property':'og:description'})['content'].
user_data['profile_image'] = soup.find('meta', {'property':'og:image'})['content']
return user_data
Пример использования #
user = scrape_instagram_user('instagram')
print(user)B. Работа с динамическим содержимым с помощью Selenium
Настройте Selenium:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
импортировать время
Настройка веб-драйвера #
chrome_options = Options()
chrome_options.add_argument("--headless")
service = ChromeService(executable_path='/path/to/chromedriver')
драйвер = webdriver.Chrome(service=service, options=chrome_options)
# Функция для получения динамического содержимого
def get_dynamic_content(url):
driver.get(url)
time.sleep(3) # Ожидание загрузки страницы
return driver.page_source
# Пример использования
html = get_dynamic_content('https://www.instagram.com/instagram/')Шаг 3: Создайте скребок для TikTok
A. Поиск общедоступных данных
Базовая настройка:
def scrape_tiktok_user(username):
url = f'https://www.tiktok.com/@{имя пользователя}'
html = get_html(url)
soup = BeautifulSoup(html, 'html.parser')
# Извлечение релевантных данных
user_data = {}
user_data['username'] = username
user_data['full_name'] = soup.find('h1', {'data-e2e':'user-title'}).text if soup.find('h1', {'data-e2e':'user-title'}) else None
user_data['description'] = soup.find('h2', {'data-e2e':'user-subtitle'}).text if soup.find('h2', {'data-e2e':'user-subtitle'}) else None
user_data['profile_image'] = soup.find('img', {'class':'avatar'})['src'] if soup.find('img', {'class':'avatar'}) else None
return user_data
Пример использования #
user = scrape_tiktok_user('tiktok')
print(user)B. Работа с динамическим содержимым с помощью Selenium
Настройте Selenium:
# Повторное использование настроек Selenium из раздела Instagram
# Пример использования для TikTok
html = get_dynamic_content('https://www.tiktok.com/@tiktok')Шаг 4: Сохраните данные в формате CSV
Сохранение данных:
def save_to_csv(data, filename='output.csv'):
df = pd.DataFrame(data)
df.to_csv(filename, index=False)
# Пример использования
data = [scrape_instagram_user('instagram'), scrape_tiktok_user('tiktok')]
save_to_csv(data)Шаг 5: Использование прокси-серверов и управление ограничением скорости
Использование прокси-серверов для сбора данных из Instagram и TikTok, например OkeyProxyПрокси-сервер для веб-скреппинга необходим для обхода ограничений скорости и IP-запреты наложенные платформой, которые призваны предотвратить чрезмерное извлечение данных и сохранить целостность сервиса. Прокси позволяют распределять запросы на скраппинг по нескольким IP-адресам, снижая вероятность быть отмеченным как подозрительный пользователь и обеспечивая постоянный доступ к нужным данным. Это особенно важно для таких платформ, как TikTok, где большие объемы запросов могут спровоцировать автоматическую защиту, блокирующую или ограничивающую доступ. Используя прокси-серверы, вы сможете поддерживать стабильную и эффективную работу по скраппингу, собирая данные без существенных сбоев.
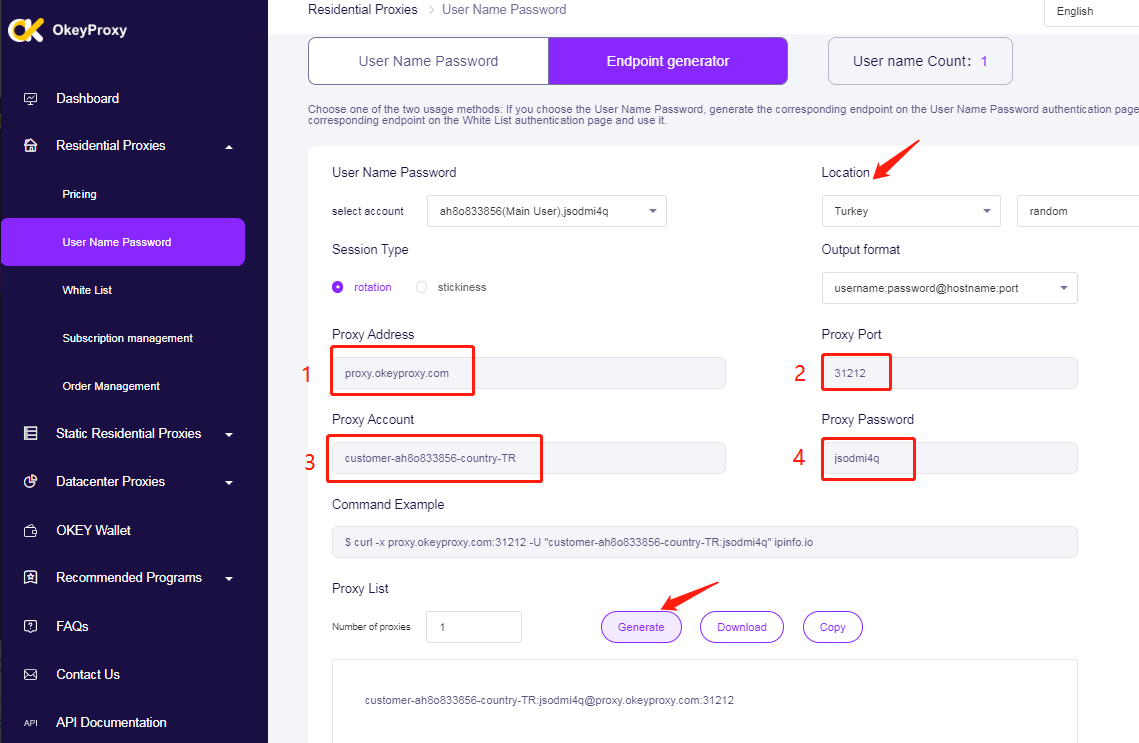
Настройка прокси-серверов:
прокси = {
'http': 'http://your_proxy_here',
'https': 'https://your_proxy_here',
}
# Пример использования с запросами
response = requests.get(url, proxies=proxies)Обработка ограничения скорости:
время импорта
Функция # для добавления задержки
def delayed_request(url, delay=2):
time.sleep(delay)
return get_html(url)Пример исследования для поиска данных в Instagram и TikTok
Сценарий
Вам поручено собрать данные профилей нескольких пользователей Instagram и TikTok, чтобы проанализировать их присутствие в социальных сетях для маркетинговой кампании.
Шаги
- Настройка среды: Убедитесь, что все необходимые библиотеки установлены, а WebDriver настроен.
- Соскабливайте данные о пользователях Instagram:
instagram_usernames = ['instagram', 'cristiano', 'natgeo']. instagram_data = [] for username in instagram_usernames: user_data = scrape_instagram_user(username) instagram_data.append(user_data) save_to_csv(instagram_data, 'instagram_users.csv') - Соскабливание данных о пользователях TikTok:
tiktok_usernames = ['tiktok', 'charlidamelio', 'therock']. tiktok_data = [] for username in tiktok_usernames: user_data = scrape_tiktok_user(username) tiktok_data.append(user_data) save_to_csv(tiktok_data, 'tiktok_users.csv') - Работа с динамическим содержимым с помощью Selenium: Используйте настройку Selenium для получения источника страницы и анализа данных для профилей с динамическим содержимым.
Другой способ: Соскоб аккаунтов пользователей из Instagram/Tiktok с помощью API
Используйте API Instagram
Instagram предлагает API, обеспечивающий доступ к публичным данным. Однако этот API ограничен и требует согласования, что делает его менее гибким для масштабного скраппинга.
- Зарегистрируйтесь для получения учетной записи разработчика на сайте Facebook для разработчиков.
- Создайте приложение Instagram Basic Display App.
- Используйте конечные точки API для доступа к данным пользователей, включая их профили и медиафайлы.

Используйте API TikTok
TikTok предоставляет публичный API для доступа к некоторым пользовательским данным, но, как и в Instagram, он имеет ограничения и требует одобрения.
- Подайте заявку на доступ к API TikTok через портал для разработчиков.
- Используйте конечные точки API для сбора пользовательских профилей и контента.

Соображения по соскабливанию учетных записей пользователей в Instagram/Tiktok
- Убедитесь, что у вас есть право на поиск данных и что вы соблюдаете условия обслуживания платформы.
- Обеспечьте правильную задержку и использование прокси-серверы чтобы избежать блокировки.
- Относитесь к полученным данным ответственно и уважайте конфиденциальность пользователей.
Резюме
Вот и все. Выполнив эти шаги по извлечению данных с помощью Python с прокси или оригинального API платформы, вы сможете эффективно скрапить аккаунты пользователей на Instagram и TikTok, оставаясь при этом в соответствии с юридическими и этическими нормами.