
Os dados são a pedra angular da análise competitiva, dos estudos de mercado e da estratégia empresarial. Uma das fontes de dados mais valiosas para as empresas de comércio eletrónico é a Amazon, o maior mercado online do mundo. A recolha de dados sobre os produtos de um vendedor na Amazon pode fornecer informações sobre estratégias de preços, ofertas de produtos e avaliações de clientes, que são cruciais para tomar decisões comerciais informadas.
Este artigo analisa o processo de recolha de dados dos produtos de um vendedor na Amazon, abrangendo ferramentas essenciais, técnicas e melhores práticas, ao mesmo tempo que aborda considerações legais e éticas.
A estrutura de dados da Amazon inclui?
O sítio Web da Amazon está estruturado de forma a categorizar produtos, análises, preços e outros detalhes. Para extrair dados de produtos de forma eficaz, é crucial compreender os seguintes componentes:
- Listagens de produtos: Contém detalhes como o nome do produto, descrição, preço e imagens.
- Informações do vendedor: Inclui classificações do vendedor, número de produtos e nome do vendedor.
- Comentários e classificações: Fornece comentários de clientes e classificações de produtos.
- Categorias de produtos: Ajuda a filtrar e organizar os produtos.
Raspar os produtos de um vendedor na Amazon passo a passo
A recolha de dados dos produtos de um vendedor na Amazon requer uma abordagem pormenorizada e estruturada, especialmente devido às sofisticadas medidas anti-resgate da Amazon. Abaixo está um tutorial abrangente, cobrindo vários aspectos do processo, desde a configuração do ambiente até lidar com desafios como CAPTCHAs e conteúdo dinâmico.
1. Preparação da recolha de dados da Web
Antes de mergulhar no processo de raspagem, certifique-se de que o seu ambiente está configurado com as ferramentas e bibliotecas necessárias.
a. Ferramentas e bibliotecas
- Python: Preferida pelo seu rico ecossistema de bibliotecas.
- Bibliotecas:
pedidos: Para efetuar pedidos HTTP.Bela Sopa: Para analisar o conteúdo HTML.Selénio: Para tratar conteúdos e interações dinâmicos.Pandas: Para manipulação e armazenamento de dados.Sucata: Se preferir uma abordagem de raspagem mais escalável e baseada em aranhas.
- Gestão de procurações:
pedidos-ip-rotador: Uma biblioteca para rotação de endereços IP.- Serviços de proxy como
OkeyProxypara proxies rotativos.
- CAPTCHA Solvers:
- Serviços como
2CaptchaouAnti-Captchapara resolver CAPTCHAs.
- Serviços como
b. Configuração do ambiente
- Instalar Python (se ainda não estiver instalado).
- Configurar um ambiente virtual:
python3 -m venv amazon-scraper fonte amazon-scraper/bin/activate - Instalar as bibliotecas necessárias:
pip install requests beautifulsoup4 selenium pandas scrapy
2. Compreender os mecanismos anti-scraping da Amazon
A Amazon utiliza várias técnicas para impedir a raspagem automática, que constituem desafios para as recolhas de dados:
- Limitação da taxa: A Amazon limita o número de pedidos que pode efetuar num curto período de tempo.
- Bloqueio de IP: Pedidos frequentes de um único IP podem levar a proibições temporárias ou permanentes.
- CAPTCHAs: Estes são apresentados para verificar se o utilizador é humano.
- Conteúdo baseado em JavaScript: Alguns conteúdos são carregados dinamicamente utilizando JavaScript, o que requer um tratamento especial.
3. Localização dos produtos do vendedor
a. Identificar o ID do vendedor
Para extrair os produtos de um vendedor específico, primeiro é necessário identificar o ID exclusivo do vendedor ou o URL da sua loja. O URL geralmente segue este formato:
https://www.amazon.com/s?me=SELLER_IDPode encontrar este URL visitando a loja do vendedor na Amazon.
b. Obter listagens de produtos
Com o ID ou URL do vendedor, pode começar a obter as listas de produtos. Uma vez que as páginas da Amazon são frequentemente paginadas, terá de lidar com a paginação para garantir que todos os produtos são recolhidos.
importar pedidos
from bs4 import BeautifulSoup
seller_url = "https://www.amazon.com/s?me=SELLER_ID"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, como Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
def get_products(seller_url):
products = []
while seller_url:
response = requests.get(vendedor_url, headers=headers)
soup = BeautifulSoup(response.content, "html.parser")
# Extrair os detalhes do produto
para produto em soup.select(".s-title-instructions-style"):
title = product.get_text(strip=True)
produtos.append(título)
# Encontrar o URL da página seguinte
página_seguinte = soup.select_one("li.a-last a")
seller_url = f "https://www.amazon.com{next_page['href']}" if next_page else None
devolver produtos
produtos = get_products(seller_url)
print(produtos)4. Manuseamento da paginação
As páginas de produtos da Amazon são frequentemente paginadas, exigindo um ciclo para percorrer cada página. A lógica para isso está incluída no obter_produtos acima, onde verifica a presença de um botão "Seguinte" e extrai o URL para a página seguinte.
5. Tratamento de conteúdos dinâmicos
Alguns pormenores do produto, como o preço ou a disponibilidade, podem ser carregados dinamicamente utilizando JavaScript. Nesses casos, é necessário utilizar Selénio ou um navegador sem cabeça como Dramaturgo para renderizar a página antes de fazer o scraping.
Utilizar o Selenium para conteúdo dinâmico
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from bs4 import BeautifulSoup
# Configurar opções do Chrome
chrome_options = Opções()
chrome_options.add_argument("--headless") # Executar em modo headless
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
# Iniciar o controlador do Chrome
service = Serviço('/caminho/para/condutor Chrome')
driver = webdriver.Chrome(service=service, options=chrome_options)
# Abrir a página do vendedor
driver.get("https://www.amazon.com/s?me=SELLER_ID")
# Aguardar que a página seja completamente carregada
driver.implicitly_wait(5)
# Analisar a fonte da página com BeautifulSoup
soup = BeautifulSoup(driver.page_source, "html.parser")
# Extrair os detalhes do produto
para produto em soup.select(".s-title-instructions-style"):
title = product.get_text(strip=True)
print(título)
driver.quit()6. Lidar com CAPTCHAs
A Amazon pode apresentar CAPTCHAs para bloquear tentativas de raspagem. Se encontrar um CAPTCHA, terá de o resolver manualmente ou utilizar um serviço como o 2Captcha para automatizar o processo.
Exemplo de utilização do 2Captcha
pedidos de importação
captcha_solution = solve_captcha("captcha_image_url") # Utilizar um serviço de resolução de CAPTCHA como o 2Captcha
# Envie a solução com o seu pedido
dados = {
'field-keywords': 'your_search_term',
'captcha': captcha_solution
}
response = requests.post("https://www.amazon.com/s", data=data, headers=headers)7. Gestão de procurações
A recolha dos produtos de um vendedor na Amazon é um caso de utilização comum para proxies, especialmente para empresas envolvidas em informações sobre preços, monitorização da concorrência ou investigação de produtos. Uma vez que a Amazon emprega fortes medidas anti-bot, proxies para extração de dados são essenciais para contornar a deteção da Amazon.
Para evitar o bloqueio de IP, é crucial utilizar proxies rotativos. Isto pode ser conseguido utilizando uma ferramenta ou serviço de gestão de proxy.
Configurando proxies com solicitações
proxies = {
"http": "http://username:password@proxy_server:port",
"https": "https://username:password@proxy_server:port",
}
response = requests.get(seller_url, headers=headers, proxies=proxies)Rodar o endereço IP com OkeyProxy
OkeyProxy é um fornecedor de proxy ideal apoiado por tecnologia patenteada, que fornece mais de 150 milhões de IPs residenciais rotativos reais e compatíveis, ligando-se rapidamente a sites alvo em qualquer país/região e contornando facilmente o bloqueio e as proibições de IP.
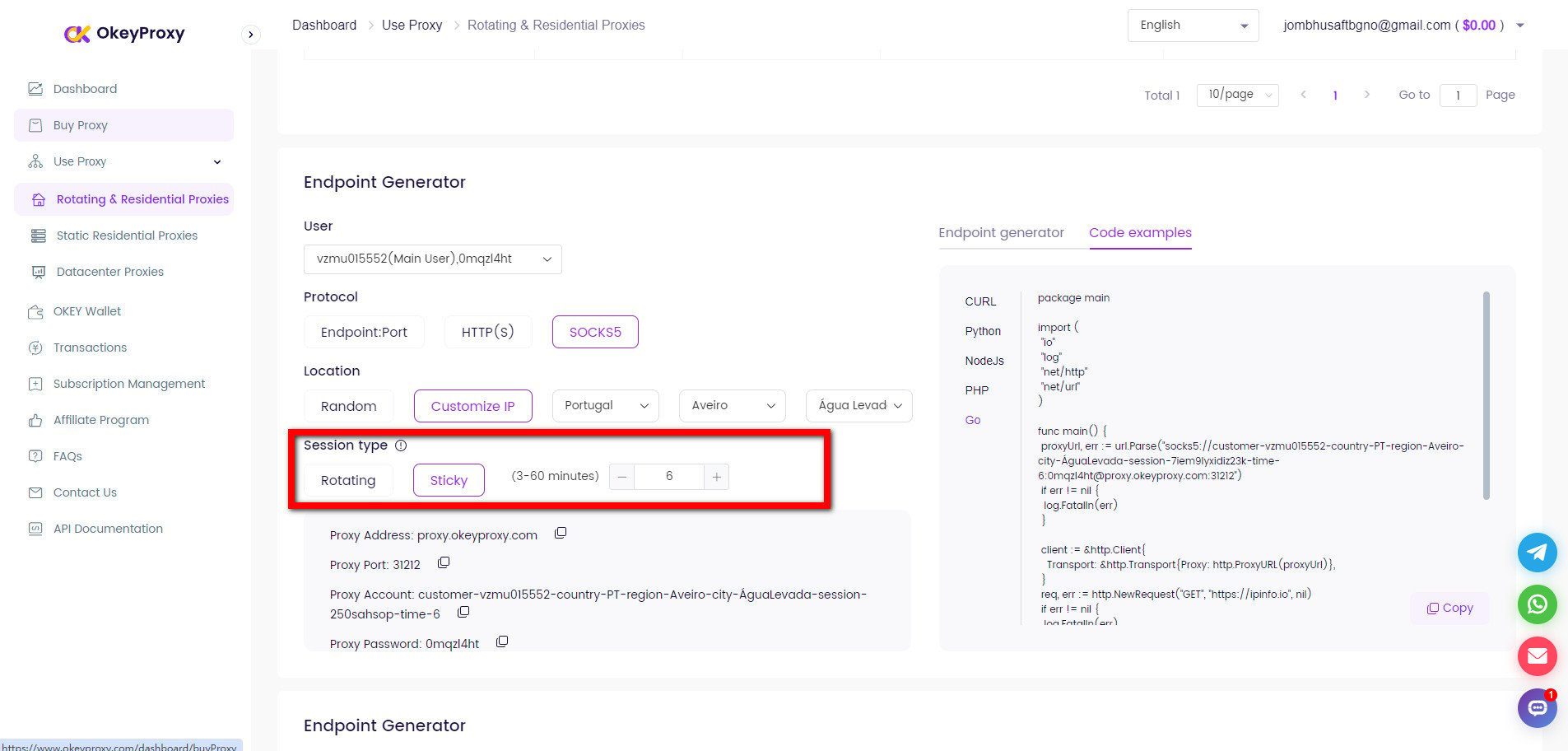
8. Armazenamento de dados
Depois de ter extraído os dados com êxito, armazene-os num formato estruturado. Pandas é uma excelente ferramenta para o efeito.
Guardar em CSV com o Pandas
importar pandas como pd
# Partindo do princípio de que os produtos são uma lista de dicionários
df = pd.DataFrame(produtos)
df.to_csv("amazon_products.csv", index=False)9. Melhores práticas e desafios
- Respeito robots.txt: Cumpra sempre as diretrizes especificadas no
robots.txtficheiro. - Limitação da taxa: Implementar estratégias de limitação de taxas para evitar a sobrecarga dos servidores da Amazon.
- Tratamento de erros: Esteja preparado para lidar com vários erros, incluindo tempos limite de pedidos, CAPTCHAs e erros de página não encontrada.
- Testes: Teste bem o seu raspador num ambiente controlado antes de o utilizar à escala.
- Legalidade: Certifique-se de que as suas actividades de recolha de dados estão em conformidade com os regulamentos legais e os termos de serviço da Amazon.
10. Dimensionamento do processo de raspagem
Para operações de raspagem em grande escala, considere a utilização de uma estrutura como Sucata ou implementando o seu raspador numa plataforma de nuvem com capacidades de rastreio distribuído.
Outro método para raspar os produtos do vendedor da Amazon
A Amazon fornece APIs como a API de publicidade de produtos para aceder a informações sobre produtos. Embora este método seja legítimo e suportado pela Amazon, requer aprovação de acesso à API e tem um âmbito limitado.
-
Prós:
Apoiado oficialmente, fiável.
-
Contras:
Acesso limitado, requer aprovação e pode implicar custos de utilização.
Perguntas frequentes sobre a recolha de dados da Amazon
Q1: É legal procurar dados de produtos na Amazon?
R: A recolha de dados da Amazon sem autorização pode violar os seus termos de serviço e pode resultar em consequências legais ou no bloqueio de endereços IP. Consulte sempre um consultor jurídico antes de prosseguir.
P2: Como evitar ser bloqueado durante a recolha de dados da Amazon?
R: Utilizar proxies para rodar o IP, respeitar o robots.txt, implementar atrasos entre os pedidos, evitar fazer scraping com demasiada frequência, etc., são algumas medidas que podem minimizar o risco de ser bloqueado pela Amazon.
P3: Porque é que o meu script de raspagem deixa de funcionar?
R: Verifique se a Amazon alterou a estrutura do seu Web site ou implementou novas medidas anti-raspagem e ajuste o script para acomodar quaisquer alterações. Além disso, verifique e mantenha regularmente o script para garantir a funcionalidade contínua.
Resumo
A raspagem dos produtos de um vendedor na Amazon envolve a identificação do URL exclusivo do vendedor, a navegação por listas de produtos paginados e o tratamento de conteúdo dinâmico com ferramentas como o Selenium. Devido às medidas anti-raspagem da Amazon, como CAPTCHAs e limitação de taxa, é essencial usar proxies rotativos e considerar a conformidade com seus termos de serviço. A utilização de bibliotecas como a BeautifulSoup para conteúdos estáticos e a Selenium para conteúdos dinâmicos, juntamente com uma gestão cuidadosa dos endereços IP e dos limites de taxa, pode ajudar a extrair e armazenar eficazmente os dados dos produtos, minimizando o risco de bloqueio.