Na era digital, os dados são frequentemente designados como o novo ouro. As empresas, os investigadores e os indivíduos dependem dos dados para tomar decisões informadas, obter conhecimentos e manter-se competitivos. O Web scraping, o processo de extração de dados de sítios Web, tornou-se uma ferramenta indispensável neste processo de pesquisa de informação. No entanto, a pesquisa na Web não está isenta de desafios, o mais proeminente dos quais é a necessidade de um agente. Neste guia completo, vamos explorar a forma como pode aproveitar os proxies de raspagem para melhorar os seus esforços de raspagem de dados e dar-lhe uma vantagem competitiva.
Saiba mais sobre Proxy Scraping
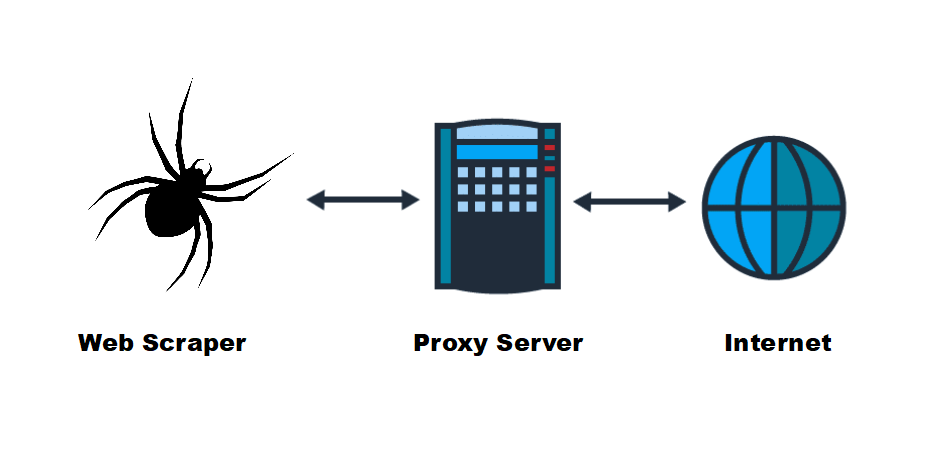
Antes de nos debruçarmos sobre a utilização de proxies para a recolha de dados da Web, vamos primeiro esclarecer o que é um proxy e o que faz. Um proxy actua como um intermediário entre o seu computador e o servidor Web a que está a tentar aceder. Quando utiliza um proxy para pedir dados a um sítio Web, o servidor proxy faz o pedido em seu nome, mascarando o seu endereço IP no processo. Isto é crucial para as pesquisas na Web, pois permite-lhe permanecer anónimo e evitar ser detectado.
Porquê utilizar um proxy para a recolha de dados da Web
A. Ultrapassar o bloqueio e as restrições de IP
Muitos sítios Web utilizam medidas anti-raspagem para impedir a recolha automática de dados. Podem bloquear endereços IP que façam demasiados pedidos num curto período de tempo ou restringir o acesso a utilizadores de regiões específicas. Ao utilizar um servidor proxy, o utilizador passa por um conjunto de endereços IP, dificultando a deteção e o bloqueio da sua atividade de pesquisa por parte dos sítios Web.
B. Garantir o anonimato e a privacidade
A recolha de várias páginas Web ou sítios Web sem um proxy pode resultar na proibição do seu endereço IP. Isto não só interrompe a recolha de dados, como também compromete a sua privacidade. Os proxies fornecem anonimato adicional, assegurando que o seu endereço IP real está oculto quando recolhe dados da Web.
Tipo de proxies de raspagem
Existem vários tipos de servidores proxy à escolha, cada um com as suas próprias vantagens e utilizações:
A. Procuração residencial
Um proxy residencial é um endereço IP atribuído a uma área residencial real. Uma vez que se assemelham a ligações de utilizadores legítimos, os sítios Web confiam neles. Os proxies residentes são ideais quando é necessário aceder a dados de um sítio Web com medidas de segurança rigorosas.
B. Proxy de centro de dados
Um proxy de centro de dados é um endereço IP alojado num centro de dados. Os proxies do centro de dados são mais rápidos e mais económicos do que os proxies residenciais, mas podem não ser tão fiáveis pelos sites. O Agente do centro de dados é adequado para tarefas que exigem velocidade e eficiência.
C.Servidor proxy SOCKS
Os servidores proxy SOCKS são versáteis e podem lidar com todos os tipos de tráfego da Internet, tornando-os uma escolha popular para pesquisas na Web. Combinam benefícios de segurança e desempenho, tornando-os uma escolha abrangente para a recolha de dados.
D. Proxy rotativo
Os proxies rotativos mudam constantemente os endereços IP, tornando difícil para os sítios Web identificar e bloquear a atividade de pesquisa. São uma escolha popular para operações de pesquisa em grande escala.
Escolha o fornecedor correto de proxies de raspagem
A escolha do fornecedor proxy correto é fundamental para o sucesso dos seus esforços de pesquisa na Web. Considere factores como fiabilidade, velocidade, cobertura de localização e preço ao escolher um fornecedor. Alguns provedores de proxy comumente usados incluem Luminati, Oxylabs e Smartproxy.
Instalar e configurar um Scraping Proxies
Configuring a proxy for web scraping requires adjusting the scraping tool’s settings so that requests are routed through the proxy server. Additionally, you may need to handle authentication and implement a proxy rotation strategy to avoid detection.
Melhores práticas para utilizar o Proxy de Scraping
A raspagem da Web não é uma panaceia, e a utilização eficaz de um servidor proxy requer a adesão às melhores práticas. Considere a utilização de limitação e estrangulamento da taxa, monitorização e registo e tratamento de erros robusto para garantir operações de pesquisa sem problemas.
Resolver problemas comuns de proxy
Apesar dos seus melhores esforços, pode deparar-se com problemas como o bloqueio de IP e CAPTCHAs ao fazer scraping na Web. Aprender a resolver estes problemas comuns relacionados com agentes é fundamental para manter um processo de recolha de dados sem problemas.
Estudo de caso
Os exemplos reais de uma recolha de dados da Web bem sucedida utilizando proxies podem fornecer-lhe informações valiosas sobre como aplicar proxies a várias situações. Estes estudos de caso ilustram os benefícios práticos da incorporação de agentes no seu fluxo de trabalho de recolha de dados.
Conclusão
Em resumo, a pesquisa na Web é uma poderosa ferramenta de recolha de dados e os agentes são a chave para desbloquear todo o seu potencial. Ao utilizar um proxy, pode ultrapassar o bloqueio de IP, garantir o anonimato e recolher dados de forma mais eficiente. Com o fornecedor de agência certo e as melhores práticas implementadas, pode melhorar os seus esforços de recolha de dados e obter uma vantagem competitiva no atual mundo orientado para os dados.


