
With the explosion of data on the internet, the need to collect, process, and analyze online information has become more important than ever. That’s where two powerful techniques come in—web crawling and web scraping. Although these terms are often used interchangeably, they are not the same. Whether you’re gathering product prices, monitoring competitor websites, or building a search index, these methods can help you automate data collection at scale.
Same? The Different Terms for Web Data Collection
What Is Web Crawling?
Web crawling is the process of automatically browsing the internet and discovering URLs or links across multiple pages. Think of it as how search engines like Google find and index new web pages.
🕷 Example:
A web crawler, also known as a spider or bot, starts from a webpage and follows all the internal/external links to discover more pages. This allows it to collect URLs, but not necessarily download or extract specific data.
Typical Use Cases:
- Building a search engine index
- Monitoring website changes at scale
- Detecting broken links on your own site
What Is Web Scraping?
Web scraping is the process of extracting specific pieces of data from one or more web pages. Instead of just discovering links, scrapers target content like product names, prices, or contact information and format it into CSV, JSON, etc.
🧲 Example:
You might scrape product prices from Walmart or other e-commerce site, job listings from a career portal, social media post statistics and so on.
Typical Use Cases:
- Price comparison tools
- Lead generation (collecting contacts from directories)
- Market research (gathering reviews, ratings)
Web Crawling Vs. Web Scraping: Key Differences
While crawlers map out the web, scrapers zero in on the information that matters.
| Aspect | Web Crawling | Web Scraping |
|---|---|---|
| Primary Goal | Discover and index web pages | Extract structured data |
| Operation | Follows links recursively | Parses and pulls specific data |
| Output | List of web pages | Structured data (CSV, JSON, etc.) |
| Complexity | Simpler per-page logic, but scale matters | Complex parsing logic per page |
| Tools & Libraries | Scrapy (Crawler), Heritrix, Apache Nutch, Requests, etc. | BeautifulSoup, Selenium, lxml, Requests, etc. |
| Target | Whole websites | Individual pages or page elements |
| Example Use | Google indexing news articles | Getting titles and authors of articles |
In many cases, both techniques are used together. A crawler finds pages, and a scraper extracts the data from them.
Python Code Snippets: Web Crawling Vs. Scraping
Let’s look at minimal Python code snippets for crawling and scraping.
How to Do Web Crawling in Python
Python makes web crawling easy with libraries like Scrapy or Requests + BeautifulSoup.
Example: Simple Web Crawler using Scrapy
# install: pip install scrapy
import scrapy
class SimpleCrawler(scrapy.Spider):
name = "simple_crawler"
start_urls = ["https://example.com"]
def parse(self, response):
# Print the page title
title = response.css('title::text').get()
yield {'url': response.url, 'title': title}
# Follow all internal links
for href in response.css('a::attr(href)').getall():
if href.startswith('/'):
yield response.follow(href, callback=self.parse)Example: Simple Web Crawler using Requests + BeautifulSoup
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
visited = set()
start_url = "https://example.com"
def crawl(url):
if url in visited:
return
visited.add(url)
try:
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
print("Crawling:", url)
for link in soup.find_all('a', href=True):
full_url = urljoin(url, link['href'])
crawl(full_url)
except Exception as e:
print("Failed to crawl:", url, "Reason:", e)
crawl(start_url) Note: Crawling large websites quickly may get your IP flagged and blocked. That’s why you need rotating IP proxies.
How to Do Web Scarping in Python
Web scraping in Python involves extracting data from websites using automated scripts. One of the most popular libraries for this task is BeautifulSoup, often used in combination with Requests.
For instance, you can locate specific tags, attributes, or classes and extract useful information like product names, prices, or headlines.
Example: Scraping Product Titles from a Page
import requests
from bs4 import BeautifulSoup
url = "https://example.com/products"
resp = requests.get(url)
soup = BeautifulSoup(resp.text, 'html.parser')
for product in soup.select(".product"):
name = product.select_one(".name").get_text(strip=True)
price = product.select_one(".price").get_text(strip=True)
print({"name": name, "price": price})You can use selectors or XPath to grab data from tables, listings, or custom HTML elements.
Tip: While web scraping and crawling are legal commonly, some websites prohibit such behavior in terms of service or their robots.txt files. Always check and see which paths are allowed or disallowed for your bot.
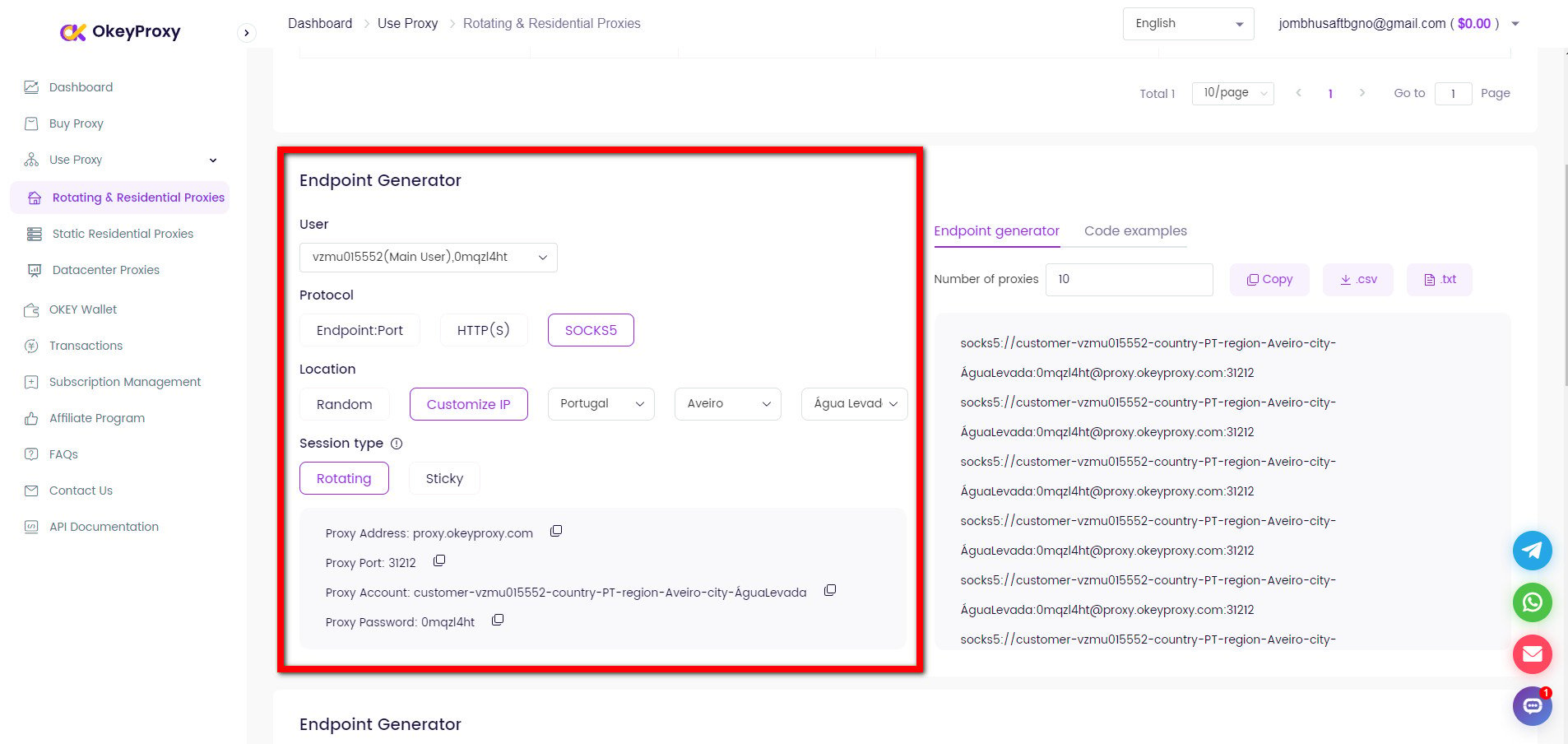
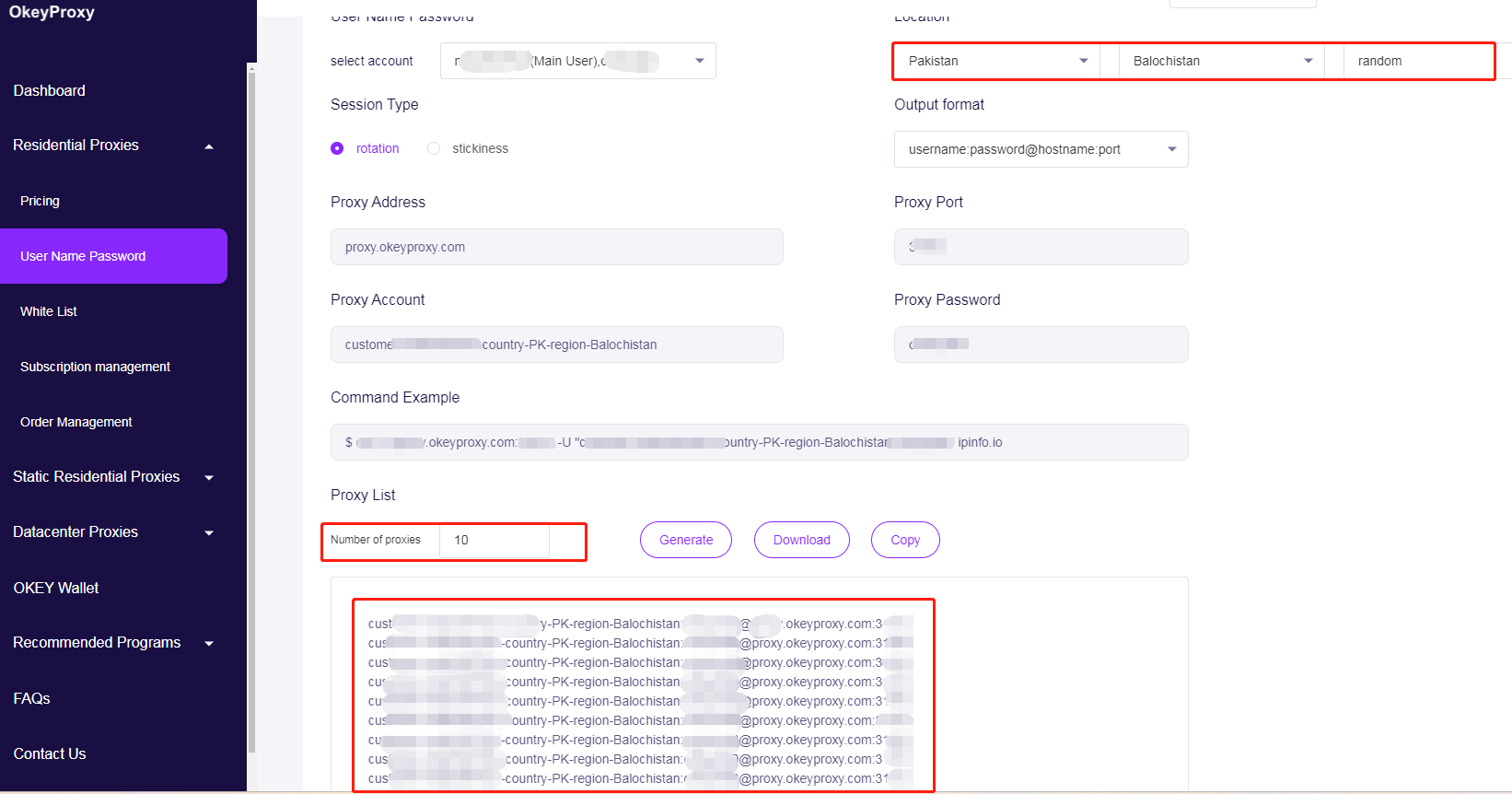
Staying Unblocked without IP Ban Using IP Proxy
Running many requests from your IP address can trigger anti-bot defenses like CAPTCHAs or outright bans from websites. To maintain reliability and speed, consider adding the usage of IP proxy, which can automatically switch between millions of real IP addresses.
Simply configure your HTTP client to use OkeyProxy with a new IP address or rotating IP addresses:
Change to New IPs to Avoid Web Crawling/Scraping Limits
proxies = {
"http": "http://username:password@proxy.okeyproxy.io:1234",
"https": "http://username:password@proxy.okeyproxy.io:1234",
}
resp = requests.get(url, headers=headers, proxies=proxies, timeout=10)Rotate Proxy IPs to Avoid Web Crawling/Scraping Limits
# Proxy pool – replace with your proxy IPs
PROXY_POOL = [
"http://username1:password@proxy.okeyproxy.io:1234",
"http://username2:password@proxy.okeyproxy.io:1234",
"http://username3:password@proxy.okeyproxy.io:1234",
"http://username4:password@proxy.okeyproxy.io:1234"
]
# Randomly select and validate a proxy from the pool
def rotate_proxy():
while True:
proxy = random.choice(PROXY_POOL)
if check_proxy(proxy):
return proxy
else:
print(f"Proxy {proxy} is not available, trying another...")
PROXY_POOL.remove(proxy)
raise Exception("No valid proxies left in the pool.")
# Check if a proxy is working by making a test request
def check_proxy(proxy):
try:
test_url = "https://httpbin.org/ip"
response = requests.get(test_url, proxies={"http": proxy}, timeout=10)
return response.status_code == 200
except:
return FalseWith a high-quality residential proxy service, you can safely run web crawlers or scrapers at scale without worrying about bans or rejections.
Which are Data Crawling and Scraping Used for?
Widely used for extracting valuable insights from the vast amounts of data available online, web crawling and web scraping have become indispensable tools underpinning today’s data economy.
On the one hand, organizations leverage web scraping to collect customer reviews, forum posts, and social media conversations for sentiment analysis. Beyond consumer sentiment analysis, data crawling powers market intelligence platforms, that the alternative data market, which includes web scraping, was valued at USD 4.9 billion in 2023 and is forecast to grow at an annual rate of 28% through 2032. In fact, 42.0% of enterprise data budgets in 2024 were allocated specifically to acquiring and processing web data, underscoring its critical role in data‑driven decision‑making. And in the retail sector, 59% of retailers use competitive price monitoring tools—often based on automated scraping—to optimize dynamic pricing strategies and boost revenue.
On the other hand, one of the primary applications of data crawling and scraping is powering AI and machine learning initiatives, with 65.0% of organizations leveraging web scraping to fuel their models. For instance, Common Crawl’s April 2024 archive collected 2.7 billion web pages (386 TiB of content), serving as a foundational dataset for major NLP model training. Besides, academic researchers and platforms like Semantic Scholar, which have indexed over 205 million scholarly papers, have also used web crawlers to index vast bodies of literature. And SEO and marketing teams employ web crawling for site audits, backlink analysis, and competitive research.
Conclusion
Web crawling is about discovering and visiting pages; web scraping is about extracting data. Python makes those two technical accessible, even for non-developers.
By combining responsible crawling, targeted scraping, and reliable management for scraping & crawling proxies, you can build powerful data pipelines that fuel analytics, machine learning models, and business insights—without interruption.
Ready to supercharge your web crawling and web scraping? Get start with a trial of OkeyProxy today and experience seamless, large-scale data collection!


Top-Notch Socks5/Http(s) Proxy Service
- Rotating Residential Proxies
- Static ISP Residential Proxies
- Datacenter Proxies
- More Custom Plans & Prices


