
Scraping user accounts on Instagram and TikTok involves collecting data from these platforms. What is important to note is that scraping these platforms could violate their terms of service and potentially lead to account bans or legal consequences. Therefore, utilize Proxy to rotate IP address is a necessary tip for web scraping. With that in mind, here’s a step-by-step guide to extract user data from Instagram/TikTok’s web interface!
How to Scrape User Accounts on IG and TikTok by Python
Let’s walk through how to scrape user profile data from Instagram and TikTok, including username, full name, description, and profile image.

Step 1: Setup Environment
- Install Python and Pip: Ensure Python is installed on your machine. You can download it from python.org. Pip, the package installer for Python, usually comes with Python installations.
- Install Required Libraries:
pip install requests beautifulsoup4 pandas selenium - Download Webdriver: For Selenium, you’ll need to download the appropriate WebDriver for your browser. For Chrome, you can get ChromeDriver from here.
Step 2: Create a Scraper for Instagram
A. Scraping Public Data
Basic Setup:
import requests
from bs4 import BeautifulSoup
import pandas as pd
# Function to get HTML content
def get_html(url):
response = requests.get(url)
return response.textExtracting User Information:
def scrape_instagram_user(username):
url = f'https://www.instagram.com/{username}/'
html = get_html(url)
soup = BeautifulSoup(html, 'html.parser')
# Extracting relevant data
user_data = {}
user_data['username'] = username
user_data['full_name'] = soup.find('meta', {'property': 'og:title'})['content'].split('•')[0].strip()
user_data['description'] = soup.find('meta', {'property': 'og:description'})['content']
user_data['profile_image'] = soup.find('meta', {'property': 'og:image'})['content']
return user_data
# Example usage
user = scrape_instagram_user('instagram')
print(user)B. Handling Dynamic Content with Selenium
Setup Selenium:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import time
# Setup WebDriver
chrome_options = Options()
chrome_options.add_argument("--headless")
service = ChromeService(executable_path='/path/to/chromedriver')
driver = webdriver.Chrome(service=service, options=chrome_options)
# Function to get dynamic content
def get_dynamic_content(url):
driver.get(url)
time.sleep(3) # Wait for the page to load
return driver.page_source
# Example usage
html = get_dynamic_content('https://www.instagram.com/instagram/')Step 3: Create a Scraper for TikTok
A. Scraping Public Data
Basic Setup:
def scrape_tiktok_user(username):
url = f'https://www.tiktok.com/@{username}'
html = get_html(url)
soup = BeautifulSoup(html, 'html.parser')
# Extracting relevant data
user_data = {}
user_data['username'] = username
user_data['full_name'] = soup.find('h1', {'data-e2e': 'user-title'}).text if soup.find('h1', {'data-e2e': 'user-title'}) else None
user_data['description'] = soup.find('h2', {'data-e2e': 'user-subtitle'}).text if soup.find('h2', {'data-e2e': 'user-subtitle'}) else None
user_data['profile_image'] = soup.find('img', {'class': 'avatar'})['src'] if soup.find('img', {'class': 'avatar'}) else None
return user_data
# Example usage
user = scrape_tiktok_user('tiktok')
print(user)B. Handling Dynamic Content with Selenium
Setup Selenium:
# Reuse the Selenium setup from the Instagram section
# Example usage for TikTok
html = get_dynamic_content('https://www.tiktok.com/@tiktok')Step 4: Save Data to CSV
Saving Data:
def save_to_csv(data, filename='output.csv'):
df = pd.DataFrame(data)
df.to_csv(filename, index=False)
# Example usage
data = [scrape_instagram_user('instagram'), scrape_tiktok_user('tiktok')]
save_to_csv(data)Step 5: Using Proxies and Handling Rate Limiting
Using proxies to scrape Instagram and TikTok, like OkeyProxy, a proxy for web scraping, is essential for circumventing rate limits and IP bans imposed by the platform, which are designed to prevent excessive data extraction and maintain the integrity of their service. Proxies allow you to distribute your scraping requests across multiple IP addresses, reducing the likelihood of being flagged as a suspicious user and ensuring continuous access to the data you need. This is especially important on platforms like TikTok, where high request volumes can trigger automated defenses that block or throttle access. By leveraging proxies, you can maintain a stable and efficient scraping operation, gathering data without facing significant disruptions.
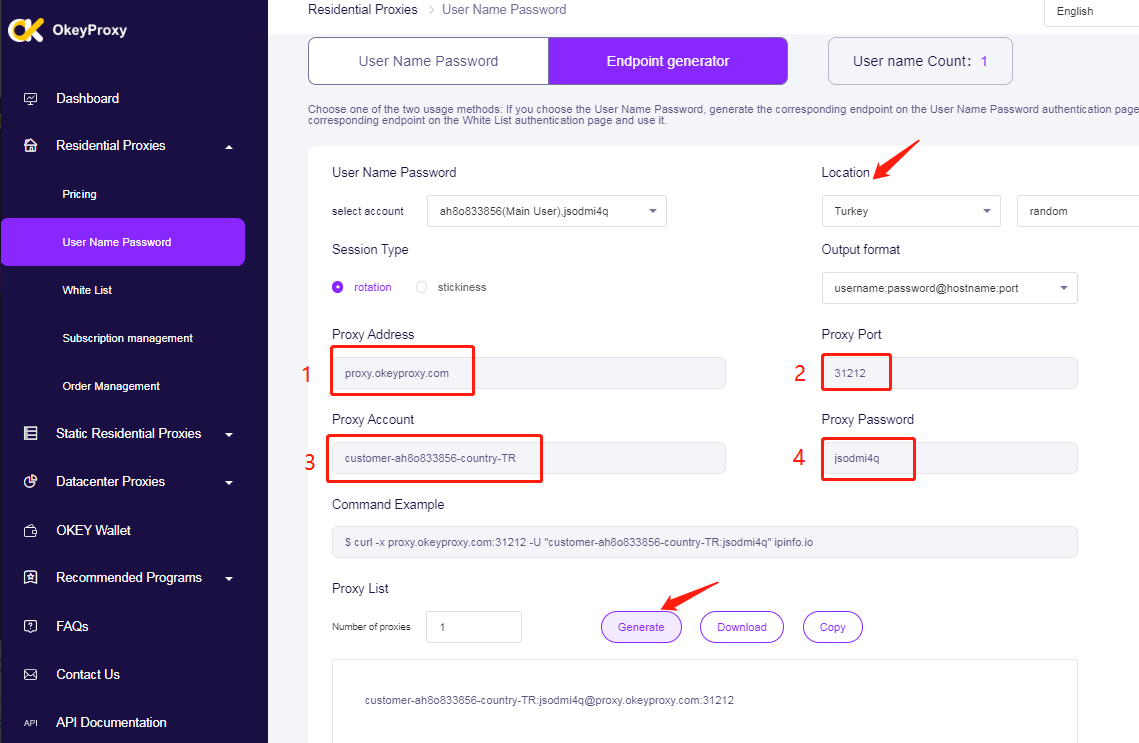
Setup Proxies:
proxies = {
'http': 'http://your_proxy_here',
'https': 'https://your_proxy_here',
}
# Example usage with requests
response = requests.get(url, proxies=proxies)Handling Rate Limiting:
import time
# Function to add delay
def delayed_request(url, delay=2):
time.sleep(delay)
return get_html(url)Case Study Example to Scrape Data on Instagram and TikTok
Scenario
You are tasked with scraping the profile data of a few Instagram and TikTok users to analyze their social media presence for a marketing campaign.
Steps
- Setup Environment: Ensure all required libraries are installed, and the WebDriver is set up.
- Scrape Instagram User Data:
instagram_usernames = ['instagram', 'cristiano', 'natgeo'] instagram_data = [] for username in instagram_usernames: user_data = scrape_instagram_user(username) instagram_data.append(user_data) save_to_csv(instagram_data, 'instagram_users.csv') - Scrape TikTok User Data:
tiktok_usernames = ['tiktok', 'charlidamelio', 'therock'] tiktok_data = [] for username in tiktok_usernames: user_data = scrape_tiktok_user(username) tiktok_data.append(user_data) save_to_csv(tiktok_data, 'tiktok_users.csv') - Handle Dynamic Content with Selenium: Use the Selenium setup to retrieve the page source and parse the data for profiles with dynamic content.
Other Way: Scrape User Accounts from Instagram/Tiktok with API
Use Instagram API
Instagram offers an API that provides access to public data. However, this API is limited and requires approval, making it less flexible for large-scale scraping.
- Register for a developer account on Facebook for Developers.
- Create an Instagram Basic Display App.
- Use the API endpoints to access user data, including user profiles and media.

Use TikTok API
TikTok provides a public API for accessing some user data, but like Instagram, it has limitations and requires approval.
- Apply for access to the TikTok API via their developer portal.
- Use API endpoints to collect user profiles and content.

Considerations to Scrape User Accounts on Instagram/Tiktok
- Ensure you have the right to scrape the data and are compliant with the platform’s terms of service.
- Implement proper delays and use proxies to avoid being blocked.
- Handle the scraped data responsibly and respect user privacy.
Summary
That’s all. By following these steps to extract data via Python with Proxy or the original API from platform, you can scrape user accounts on Instagram and TikTok effectively while staying compliant with legal and ethical guidelines.
