
InstagramとTikTokのユーザーアカウントをスクレイピングする は、これらのプラットフォームからデータを収集することを含む。注意しなければならないのは、これらのプラットフォームをスクレイピングすることは、そのプラットフォームの利用規約に違反する可能性があり、アカウント禁止や法的措置につながる可能性があるということだ。したがって プロキシ IPアドレスをローテーションすることは、ウェブスクレイピングに必要なヒントだ。これを念頭に置いて、Instagram/TikTokのウェブインターフェースからユーザーデータを抽出するためのステップバイステップガイドを紹介しよう!
PythonでIGとTikTokのユーザーアカウントをスクレイピングする方法
InstagramとTikTokからユーザー名、フルネーム、説明、プロフィール画像などのプロフィールデータをスクレイピングする方法を説明しよう。

ステップ1:環境の設定
- PythonとPipをインストールする: Pythonがあなたのマシンにインストールされていることを確認してください。Pythonは python.org.PipはPythonのパッケージインストーラで、通常Pythonのインストールに付属しています。
- 必要なライブラリをインストールする:
pip install requests beautifulsoup4 pandas selenium - Webdriverをダウンロードする: Seleniumの場合は、ブラウザに適したWebDriverをダウンロードする必要があります。Chromeの場合、ChromeDriverは以下から入手できます。 これ.
ステップ2:Instagram用のスクレイパーを作成する
A.公共データのスクレイピング
基本的なセットアップ:
インポートリクエスト
from bs4 import BeautifulSoup
import pandas as pd
# HTMLコンテンツを取得する関数
def get_html(url):
response = requests.get(url)
return response.textユーザー情報の抽出:
def scrape_instagram_user(username):
url = f'https://www.instagram.com/{username}/'
html = get_html(url)
soup = BeautifulSoup(html, 'html.parser')
# 関連データの抽出
user_data={}とする。
user_data['username'] = ユーザー名
user_data['full_name'] = soup.find('meta', {'property': 'og:title'})['content'].split('-')[0].strip()
user_data['description'] = soup.find('meta', {'property': 'og:description'})['content'].
user_data['profile_image'] = soup.find('meta', {'property': 'og:image'})['content'].
return user_data
# 使用例
user = scrape_instagram_user('instagram')
print(user)B.Seleniumで動的コンテンツを扱う
Seleniumをセットアップする:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
インポート時間
#セットアップWebDriver
chrome_options = Options()
chrome_options.add_argument("--headless")
service = ChromeService(executable_path='/path/to/chromedriver')
driver = webdriver.Chrome(service=service, options=chrome_options)
# ダイナミックコンテンツを取得する関数
def get_dynamic_content(url):
driver.get(url)
time.sleep(3) # ページがロードされるまで待つ
return driver.page_source
# 使用例
html = get_dynamic_content('https://www.instagram.com/instagram/')ステップ3:TikTok用のスクレイパーを作成する
A.公共データのスクレイピング
基本的なセットアップ:
def scrape_tiktok_user(username):
url = f'https://www.tiktok.com/@{username}'
html = get_html(url)
soup = BeautifulSoup(html, 'html.parser')
# 関連データの抽出
user_data={}とする。
user_data['username'] = ユーザー名
user_data['full_name'] = soup.find('h1', {'data-e2e': 'user-title'}).text if soup.find('h1', {'data-e2e': 'user-title'}) else なし
user_data['description'] = soup.find('h2', {'data-e2e': 'user-subtitle'}).text if soup.find('h2', {'data-e2e': 'user-subtitle'}) else なし
user_data['profile_image'] = soup.find('img', {'class': 'avatar'})['src'] if soup.find('img', {'class': 'avatar'}) else なし
return user_data
# 使用例
user = scrape_tiktok_user('tiktok')
print(user)B.Seleniumで動的コンテンツを扱う
Seleniumをセットアップする:
# インスタグラムセクションのSeleniumセットアップを再利用する
# TikTokでの使用例
html = get_dynamic_content('https://www.tiktok.com/@tiktok')ステップ4:データをCSVに保存する
データの保存:
def save_to_csv(data, filename='output.csv'):
df = pd.DataFrame(data)
df.to_csv(filename, index=False)
# 使用例
data = [scrape_instagram_user('instagram'), scrape_tiktok_user('tiktok')].
save_to_csv(data)ステップ5:プロキシの使用とレート制限の処理
インスタグラムやTikTokをスクレイピングするためにプロキシを使う。 オッケープロキシー, a ウェブスクレイピング用プロキシ料金制限を回避するために不可欠である。 IP禁止 これは、過剰なデータ抽出を防止し、サービスの完全性を維持するために設計されています。プロキシを使用することで、スクレイピングのリクエストを複数のIPアドレスに分散させることができ、不審なユーザーとしてフラグを立てられる可能性を減らし、必要なデータへの継続的なアクセスを確保することができます。これはTikTokのようなプラットフォームでは特に重要で、リクエスト量が多いと、アクセスをブロックしたりスロットルしたりする自動化された防御機能が作動する可能性があります。プロキシを活用することで、安定した効率的なスクレイピング作業を維持し、大きな中断に直面することなくデータを収集することができます。
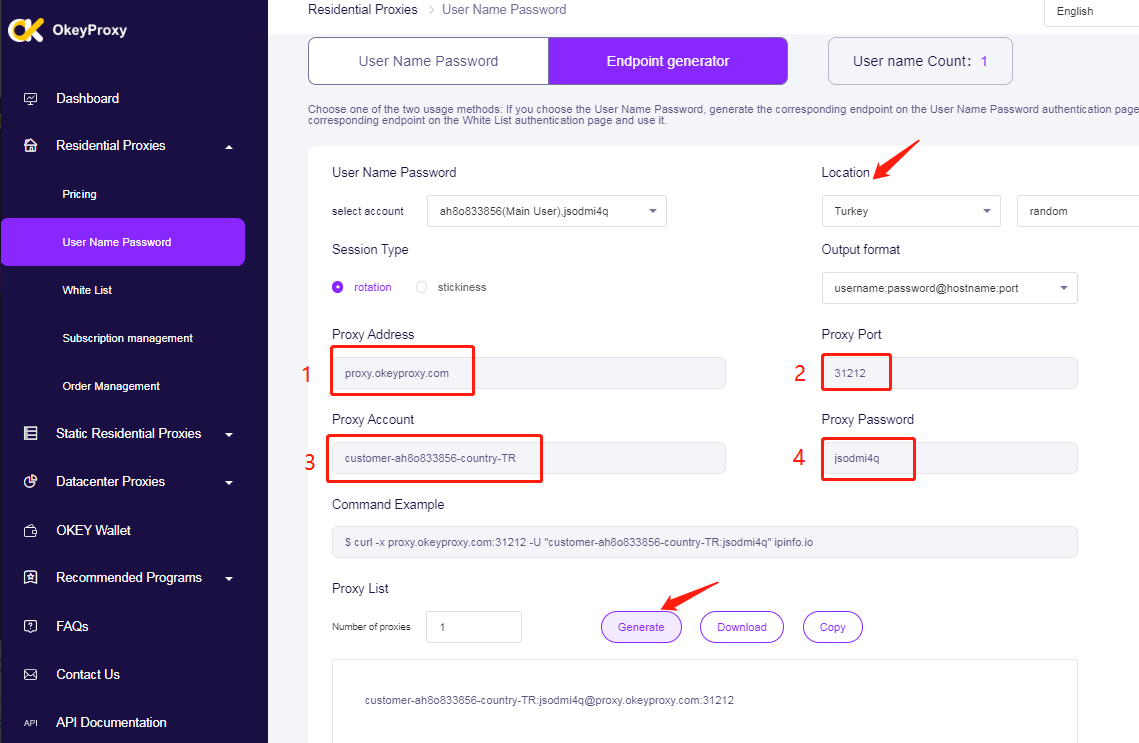
プロキシを設定する:
プロキシ = {
'http':'http://your_proxy_here'、
https': 'https://your_proxy_here'、
}
# requestsでの使用例
response = requests.get(url, proxies=proxies)レート制限の処理:
インポート時間
# 遅延を追加する関数
def delayed_request(url, delay=2):
time.sleep(delay)
return get_html(url)インスタグラムとTikTokのデータをスクレイピングするケーススタディ例
シナリオ
あなたは、マーケティングキャンペーンのために、数人のInstagramとTikTokユーザーのプロフィールデータをスクレイピングし、彼らのソーシャルメディアにおけるプレゼンスを分析する仕事を任されている。
ステップ
- セットアップ環境: 必要なライブラリーがすべてインストールされ、WebDriverがセットアップされていることを確認する。
- インスタグラムのユーザーデータをかき集める:
instagram_usernames = ['instagram', 'cristiano', 'natgeo'] ]。 instagram_data = []. for username in instagram_usernames: user_data = scrape_instagram_user(username) instagram_data.append(user_data) save_to_csv(instagram_data, 'instagram_users.csv') - TikTokのユーザーデータをかき集める:
tiktok_usernames = ['tiktok','charlidamelio','therock']。 tiktok_data = []. for username in tiktok_usernames: user_data = scrape_tiktok_user(username) tiktok_data.append(user_data) save_to_csv(tiktok_data, 'tiktok_users.csv') - Seleniumで動的コンテンツを扱う Seleniumセットアップを使用してページソースを取得し、動的コンテンツを持つプロファイルのデータを解析する。
他の方法:APIを使ってInstagram/Tiktokからユーザーアカウントをスクレイピングする
インスタグラムAPIを使用する
Instagramは公開データへのアクセスを提供するAPIを提供している。しかし、このAPIは限定的で承認が必要なため、大規模なスクレイピングには柔軟性に欠ける。
- Facebook for Developersで開発者アカウントを登録する。
- インスタグラムの基本表示アプリを作成する。
- APIエンドポイントを使用して、ユーザープロファイルやメディアを含むユーザーデータにアクセスします。

TikTok APIを使用する
TikTokは一部のユーザーデータにアクセスするためのパブリックAPIを提供しているが、Instagramのように制限があり、承認が必要である。
- 開発者ポータルからTikTok APIへのアクセスを申請する。
- APIエンドポイントを使用して、ユーザープロファイルとコンテンツを収集します。

Instagram/Tiktokのユーザーアカウントをスクレイピングするための考察
- データをスクレイピングする権利があり、プラットフォームの利用規約を遵守していることを確認する。
- 適切な遅延と使用を実施する 代理人 ブロックされないように
- スクレイピングされたデータを責任を持って扱い、ユーザーのプライバシーを尊重すること。
概要
以上だ。以上の手順に従い、Python with ProxyまたはプラットフォームからオリジナルのAPIを使用してデータを抽出することで、InstagramとTikTokのユーザーアカウントを効果的にスクレイピングしながら、法的および倫理的ガイドラインを遵守することができます。









