
ウェブスクレイピングの領域では、プロキシはスムーズで中断のないデータ収集を保証する重要な役割を果たします。ウェブサイトから大量のデータをスクレイピングする場合、IPブロックやレート制限に遭遇することがよくあります。このような制限を回避し、より効率的で匿名性の高いスクレイピングを実現するために、プロキシスクレーパープロキシーが重宝されています。
このブログでは、プロキシー・スクレーパープロキシーとは何か、なぜスクレイピングに不可欠なのか、そしてニーズに合ったプロキシー・スクレーパーの利用方法について説明する。
プロクシ・スクレーパーとは?
プロキシ・スクレイパーは、ウェブ・スクレイピングの際に使用される特殊なプロキシです。プロキシは、スクレイピングツールとターゲットウェブサイトの仲介役となり、あなたの実際のIPアドレスを隠します。使用方法 ローテーションIPアドレスこれらのプロキシは、スクレイピング防止機構を備えたウェブサイトによって検出されたりブロックされたりするのを避けるのに役立つ。
- IPローテーション: IPアドレスを自動的に切り替えて検知を回避する。
- ジオ・ターゲティング: 特定の国や地域のIPを選択できるようにする。
- 高い匿名性: スクレイピング中にあなたの身元を隠します。
- スピードと信頼性: 中断のないスムーズなデータ収集を実現。
なぜプロキシ・スクレーパーが重要なのか?
- ウェブサイトは同じIPからの繰り返しのリクエストをブロックすることが多い。プロキシは複数のIPにリクエストを分散させ、検知されるリスクを低減します。
- プロキシ・スクレーパー・プロキシは、さまざまなIPにトラフィックを分散させることで、レート制限を処理するのに役立つ。
- プロキシを使用すると、現在地を隠して地域固有のコンテンツを表示できます。
- CAPTCHAやブロックを避け、スムーズなデータ収集を実現。
スクレイピング用プロキシの種類
-
レジデンシャル・プロキシ:
ISPから実際のデバイスに割り当てられ、匿名性が高く、厳格なウェブサイトに最適。
-
データセンター・プロキシ:
より速く、より安く、安全性の低いサイトに適している。
-
プロキシのローテーション:
大規模なスクレイピングのためにIPを自動的に変更する。
-
静的プロキシ:
セッションの一貫性を保つために、同じIPアドレスを維持する。
最適なプロキシスクレーパーの選び方
以下のヒントに従って、ニーズに合ったプロキシを選択してください:
1.ターゲットのウェブサイトを考える
- 用途 レジデンシャル・プロキシ セキュリティの高いウェブサイト向け。
- データセンター・プロキシ 安全性の低いサイトではうまく機能する。
2.回転オプションを探す
プロキシをローテーションさせることで、発見されるリスクを減らし IP禁止.
3.スピードとアップタイムのチェック
スクレイピング中の中断を避けるために、プロキシスクレーパーが高速で信頼できるアップタイムを提供していることを確認する。
4.ジオターゲティング機能
特定の地域からのデータが必要な場合は、ジオターゲティングが可能なプロキシを選択します。(OkeyProxyは200以上の国と地域から150M以上のIPを提供し、都市ターゲティングと プロバイダー をターゲットにしている。)
スクレイピングのための推奨プロキシ・プロバイダー
効率的で信頼性の高いウェブスクレイピングのためには、信頼できるプロキシプロバイダーの利用が不可欠である。 オッケープロキシー は素晴らしい選択だ:
- 居住者用プロキシのローテーション: IPバンを回避し、地域固有のコンテンツにアクセスするのに最適だ。
- 高速データセンタープロキシ: 迅速かつ大規模な掻き取り作業に最適。
- 全世界をカバー: 世界各地からのプロキシを使用し、地域を絞ったスクレイピングを行います。

プロキシスクレーパーの使用手順
プロキシの使用は、匿名性を維持し、IPバンを回避し、制限を回避するために、Webスクレイピングに不可欠です。以下は、スクレイピングのためにプロキシを効果的に使用するための詳細な手順です:
前へプロキシの詳細を取得
様々なスクレイピング・ニーズに適したプロキシがある:信頼できるプロバイダーを使用する、 オッケープロキシー高品質なプロキシサービスを提供し、ダッシュボードからIPアドレス、ポート、その他の情報を取得します。


一流のSocks5/http(s)プロキシ・サービス
- Rotating Residential Proxies
- Static ISP Residential Proxies
- Datacenter Proxies
- More Custom Plans & Prices
注意:スクレイピング用の無料プロキシは、潜在的なセキュリティ・リスクや不安定性があるため避けること。
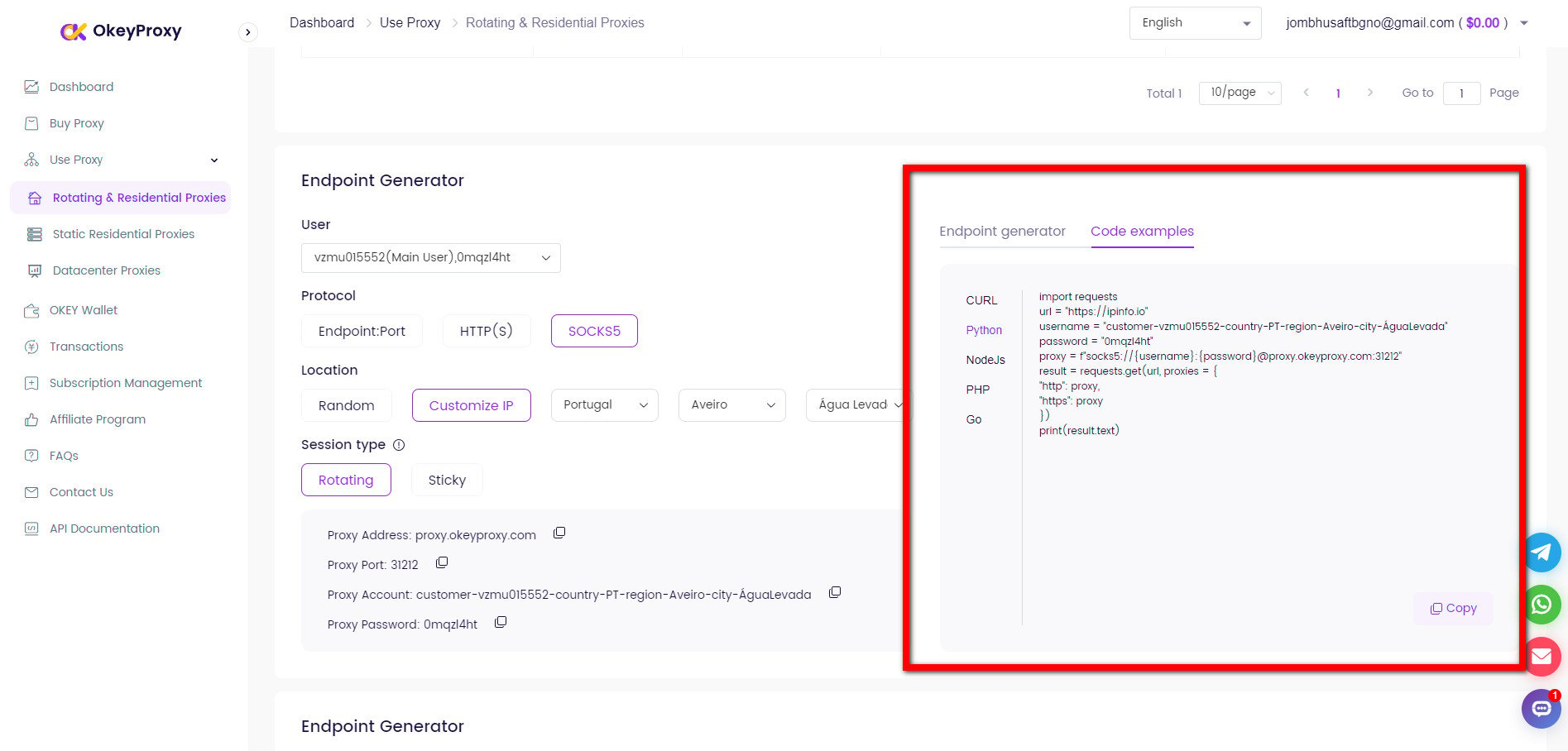
1.ブラウザベースのスクレイピング
Seleniumのようなツールの場合:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--proxy-server=http://your-proxy-server:port')
driver = webdriver.Chrome(options=chrome_options)
driver.get('http://example.com')2.コマンドラインツール
のようなツールの場合 cURL:
curl -x http://proxy-server:port http://example.com3.ライブラリ(例:Pythonのリクエスト)
プロキシを リクエスト 図書館 パイソン:
輸入リクエスト
プロキシ = {
"http":"http://your-proxy-server:port"、
「https":"http://your-proxy-server:port"、
}
response = requests.get('http://example.com', proxies=proxies)
print(response.text)4.認証
プロキシが認証を必要とする場合は、認証情報を提供する:
プロキシ = {
「http":"http://username:password@proxy-server:port"、
「https":"http://username:password@proxy-server:port"、
}5.ハンドルの回転/速度制限
大規模な削り取り用:
- 用途 回転プロキシ への IPを変更する 各リクエストの後に
- 人間の行動を模倣するために、リクエストの間に遅延を組み込む。
例 リクエスト そして 時間 遅延のため
インポート時間
for url in url_list:
response = requests.get(url, proxies=proxies)
print(response.status_code)
time.sleep(2) # リクエスト間の遅延結論
プロキシスクレイパーは、ブロックを回避し、検出を回避し、データへの中断のないアクセスを保証するため、ウェブスクレイピングを成功させるために不可欠です。調査、SEO、ビジネスの洞察のためのスクレイピングであろうと、適切なプロキシに投資することで、時間と労力を節約し、効率を高めることができます。
スクレイピングのニーズをサポートする信頼性の高いプロキシスクレーパーをお探しですか?以下のオプションをご検討ください。 オッケープロキシーウェブスクレイピング作業に最適な高速で安全なプロキシを提供する。