1. Che cos'è Scrapy CrawlSpider?
CrawlSpider è una classe derivata di Scrapy e il principio di progettazione della classe Spider è quello di effettuare il crawling solo delle pagine web presenti nell'elenco start_url. Al contrario, la classe CrawlSpider definisce alcune regole per fornire un meccanismo conveniente per seguire i link - estrarre i link dallo scraping Amazon pagine web e continuare il crawling.
CrawlSpider può abbinare gli URL che soddisfano determinate condizioni, assemblarli in oggetti Request e inviarli automaticamente al motore, specificando una funzione di callback. In altre parole, il crawler CrawlSpider può recuperare automaticamente le connessioni secondo regole predefinite.
2. Creare un crawler CrawlSpider per lo scraping di Amazon
scrapy genspider -t crawl spider_name domain_nameCreare il comando Scraping Amazon crawler:
Ad esempio, per creare un crawler Amazon chiamato "amazonTop":
scrapy genspider -t crawl amzonTop amazon.comLe parole che seguono rappresentano l'intero codice:
importare scrapy
da scrapy.linkextractors import LinkExtractor
da scrapy.spiders import CrawlSpider, Rule
classe TSpider(CrawlSpider):
name = 'amzonTop '
domini_ammessi = ['amazon.com']
start_urls = ['https://amazon.com/']
regole = (
Regola(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
item = {}
# item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
# item['name'] = response.xpath('//div[@id="name"]').get()
# item['description'] = response.xpath('//div[@id="description"]').get()
restituire l'elemento
Rules è una tupla o un elenco contenente oggetti Rule. Una regola è composta da parametri come LinkExtractor, callback e follow.
A. LinkExtractor: Un estrattore di link che corrisponde agli indirizzi URL usando regex, XPath o CSS.
B. callback: Una funzione di callback per gli indirizzi URL estratti, opzionale.
C. seguire: Indica se le risposte corrispondenti agli indirizzi URL estratti continueranno a essere elaborate dalle regole. Vero significa che lo faranno, Falso significa che non lo faranno.
3. Scraping dei dati dei prodotti Amazon
3.1 Creare un crawler Amazon per lo scraping
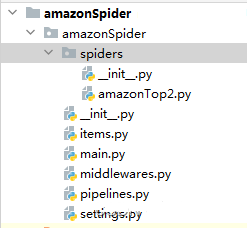
scrapy genspider -t crawl amazonTop2 amazon.comLa struttura del Codice Spider:
3.2 Estrarre gli URL per la consultazione dell'elenco dei prodotti e dei dettagli dei prodotti.
A. Estrarre tutti gli Asin e i rank dei prodotti dalla pagina dell'elenco dei prodotti, cioè recuperare Asin e rank dalla pagina scatole blu nell'immagine.
B. Estrarre Asin per tutti i colori e le specifiche dalla pagina dei dettagli del prodotto, cioè recuperare Asin dal file scatole verdi, che includono Asin dalle scatole blu.
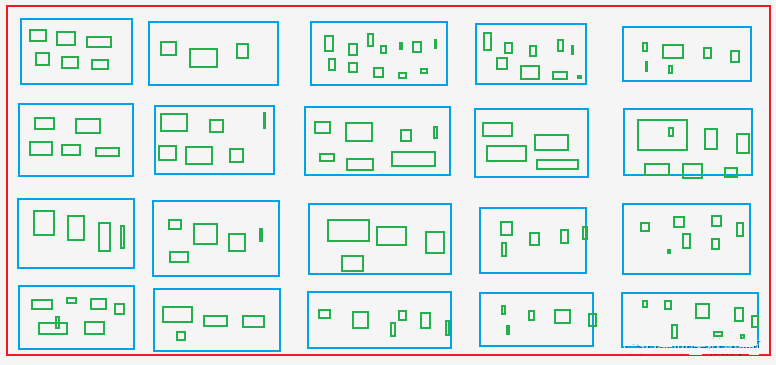
Le caselle verdi: Come le taglie X, M, L, XL e XXL per i vestiti nei siti di shopping.
File ragno: amzonTop2.py
importare datetime
importare re
importare tempo
da copy import deepcopy
importare scrapy
da scrapy.linkextractors import LinkExtractor
da scrapy.spiders import CrawlSpider, Rule
classe Amazontop2Spider(CrawlSpider):
name = 'amazonTop2'
domini_ammessi = ['amazon.com']
# https://www.amazon.com/Best-Sellers-Tools-Home-Improvement-Wallpaper/zgbs/hi/2242314011/ref=zg_bs_pg_2?_encoding=UTF8&pg=1
start_urls = ['https://amazon.com/Best-Sellers-Tools-Home-Improvement-Wallpaper/zgbs/hi/2242314011/ref=zg_bs_pg_2']
regole = [
Rule(LinkExtractor(restrict_css=('.a-selected','.a-normal')), callback='parse_item', follow=True),
]
def parse_item(self, response):
asin_list_str = "".join(response.xpath('//div[@class="p13n-desktop-grid"]/@data-client-recs-list').extract())
se asin_list_str:
asin_list = eval(asin_list_str)
per asinDict in asin_list:
item = {}
se "'id'" in str(asinDict):
listProAsin = asinDict['id']
pro_rank = asinDict['metadataMap']['render.zg.rank']
item['rank'] = pro_rank
item['ListAsin'] = listProAsin
item['rankAsinUrl'] =f "https://www.amazon.com/Textile-Decorative-Striped-Corduroy-Pillowcases/dp/{listProAsin}/ref=zg_bs_3732341_sccl_1/136-3072892-8658650?psc=1"
print("-"*30)
print(item)
print('-'*30)
yield scrapy.Request(item["rankAsinUrl"], callback=self.parse_list_asin,
meta={"main_info": deepcopy(item)})
def parse_list_asin(self, response):
"""
:param risposta:
:return:
"""
news_info = response.meta["main_info"]
list_ASIN_all_findall = re.findall('"colorToAsin":(.*?), "refactorEnabled":true,', str(response.text))
try:
try:
parentASIN = re.findall(r', "parentAsin":"(.*?)",', str(response.text))[-1]
except:
parentASIN = re.findall(r'&parentAsin=(.*?)&', str(response.text))[-1]
eccezione: parentASIN = ''', str(response.text)[-1]
parentASIN = ''
# parentASIN = parentASIN[-1] if parentASIN !=[] else ""
print("parentASIN:",parentASIN)
se list_ASIN_all_findall:
list_ASIN_all_str = "".join(list_ASIN_all_findall)
list_ASIN_all_dict = eval(list_ASIN_all_str)
per asin_min_key, asin_min_value in list_ASIN_all_dict.items():
se asin_min_valore:
asin_min_value = asin_min_value['asin']
news_info['parentASIN'] = parentASIN
news_info['secondASIN'] = asin_min_value
news_info['rankSecondASINUrl'] = f "https://www.amazon.com/Textile-Decorative-Striped-Corduroy-Pillowcases/dp/{asin_min_value}/ref=zg_bs_3732341_sccl_1/136-3072892-8658650?psc=1"
yield scrapy.Request(news_info["rankSecondASINUrl"], callback=self.parse_detail_info,meta={"news_info": deepcopy(news_info)})
def parse_detail_info(self, response):
"""
:param response:
:return:
"""
item = response.meta['news_info']
ASIN = item['secondASIN']
# print('--------------------------------------------------------------------------------------------')
# con open('amazon_h.html', 'w') as f:
# f.write(response.body.decode())
# print('--------------------------------------------------------------------------------------------')
pro_details = response.xpath('//table[@id="productDetails_detailBullets_sections1"]//tr')
pro_detail = {}
per pro_row in pro_details:
pro_detail[pro_row.xpath('./th/text()').extract_first().strip()] = pro_row.xpath('./td//text()').extract_first().strip()
print("pro_detail",pro_detail)
ships_from_list = response.xpath(
'//div[@tabular-attribute-name="Navi da"]/div//span//text()').extract()
# 物流方
try:
delivery = ships_from_list[-1]
except:
consegna = ""
seller = "".join(response.xpath('//div[@id="tabular-buybox"]//div[@class="tabular-buybox-text"][3]//text()').extract()).strip().replace("'", "")
se venditore == "":
seller = "".join(response.xpath('//div[@class="a-section a-spacing-base"]/div[2]/a/testo()').extract()).strip().replace("'", "")
seller_link_str = "".join(response.xpath('//div[@id="tabular-buybox"]//div[@class="tabular-buybox-text"][3]//a/@href').extract())
# if seller_link_str:
# seller_link = "https://www.amazon.com" + seller_link_str
# altrimenti:
# seller_link = ''
seller_link = "https://www.amazon.com" + seller_link_str if seller_link_str else ''
brand_link = response.xpath('//div[@id="bylineInfo_feature_div"]/div[@class="a-section a-spacing-none"]/a/@href').extract_first()
pic_link = response.xpath('//div[@id="main-image-container"]/ul/li[1]//img/@src').extract_first()
title = response.xpath('//div[@id="titleSection"]/h1//text()').extract_first()
star = response.xpath('//div[@id="averageCustomerReviews_feature_div"]/div[1]//span[@class="a-icon-alt"]//text()').extract_first().strip()
try:
price = response.xpath('//div[@class="a-section a-spacing-none aok-align-center"]/span[2]/span[@class="a-offscreen"]//text()').extract_first()
except:
try:
price = response.xpath('//div[@class="a-section a-spacing-none aok-align-center"]/span[1]/span[@class="a-offscreen"]//text()').extract_first()
except:
prezzo = ''
size = response.xpath('//li[@class="swatchSelect"]//p[@class="a-text-left a-size-base"]//text()').extract_first()
key_v = str(pro_detail.keys())
brand = pro_detail['Brand'] if "Brand" in key_v else ''
se marca == '':
brand = response.xpath('//tr[@class="a-spacing-small po-brand"]/td[2]//text()').extract_first().strip()
elif brand == "":
brand = response.xpath('//div[@id="bylineInfo_feature_div"]/div[@class="a-section a-spacing-none"]/a/text()').extract_first().replace("Brand: ", "").replace("Visit the", "").replace("Store", '').strip()
color = pro_detail['Color'] if "Color" in key_v else ""
se colore == "":
color = response.xpath('//tr[@class="a-spacing-small po-color"]/td[2]//text()').extract_first()
elif color == '':
color = response.xpath('//div[@id="variation_color_name"]/div[@class="a-row"]/span//text()').extract_first()
pattern = pro_detail['Pattern'] if "Pattern" in key_v else ""
se pattern == "":
pattern = response.xpath('//tr[@class="a-spacing-small po-pattern"]/td[2]//text()').extract_first().strip()
materiale #
prova:
materiale = pro_detail['Materiale']
except:
material = response.xpath('//tr[@class="a-spacing-small po-material"]/td[2]//text()').extract_first().strip()
Forma #
shape = pro_detail['Shape'] if "Shape" in key_v else ""
se forma == "":
shape = response.xpath('//tr[@class="a-spacing-small po-item_shape"]/td[2]//text()').extract_first().strip()
stile #
# cinque_punti
five_points =response.xpath('//div[@id="feature-bullets"]/ul/li[position()>1]//text()').extract_first().replace("\"", "'")
size_num = len(response.xpath('//div[@id="nome_dimensione_variante"]/ul/li').extract())
color_num = len(response.xpath('//div[@id="variation_color_name"]//li').extract())
# variante_num =
stile #
# produttore
provare:
Produttore = pro_detail['Produttore'] if "Produttore" in str(pro_detail) else " "
except:
Produttore = ""
item_weight = pro_detail['Item Weight'] if "Weight" in str(pro_detail) else ''
product_dim = pro_detail['Product Dimensions'] if "Product Dimensions" in str(pro_detail) else ''
# materiale_prodotto
try:
product_material = pro_detail['Material']
except:
materiale_prodotto = ''
# tipo_tessuto
try:
fabric_type = pro_detail['Fabric Type'] if "Fabric Type" in str(pro_detail) else " "
except:
fabric_type = ""
star_list = response.xpath('//table[@id="histogramTable"]//tr[@class="a-histogram-row a-align-center"]//td[3]//a/text()').extract()
se star_list:
try:
star_1 = star_list[0].strip()
except:
stella_1 = 0
try:
star_2 = star_list[1].strip()
eccezione: stella_2 = 0
star_2 = 0
prova:
star_3 = star_list[2].strip()
eccezione: stella_3 = 0
stella_3 = 0
prova:
star_4 = star_list[3].strip()
eccezione: stella_4 = 0
star_4 = 0
prova:
star_5 = star_list[4].strip()
eccezione: stella_5 = 0
stella_5 = 0
else:
stella_1 = 0
stella_2 = 0
stella_3 = 0
stella_4 = 0
stella_5 = 0
se "Data prima disponibilità" in str(pro_detail):
data_first_available = pro_detail['Date First Available']
if data_first_available:
data_first_available = datetime.datetime.strftime(
datetime.datetime.strptime(data_first_available, '%B %d, %Y'), '%Y/%m/%d')
altrimenti:
data_first_available = ""
reviews_link = f'https://www.amazon.com/MIULEE-Decorative-Pillowcase-Cushion-Bedroom/product-reviews/{ASIN}/ref=cm_cr_arp_d_viewopt_fmt?ie=UTF8&reviewerType=all_reviews&formatType=current_format&pageNumber=1'
# numero_recensioni, numero_valutazioni
scrap_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
elemento['consegna']=consegna
elemento['venditore']=venditore
item['link_venditore']= link_venditore
item['brand_link']= brand_link
item['pic_link'] =pic_link
elemento['titolo']=titolo
elemento['marchio']=marchio
voce['stella']=stella
voce['prezzo']=prezzo
voce['colore']=colore
articolo['modello']=modello
voce['materiale']=materiale
voce['forma']=forma
item['five_points']=cinque_punti
item['size_num']=size_num
item['color_num']=color_num
voce['Produttore']=Produttore
articolo['peso_voce']=peso_voce
item['product_dim']=dimensione_prodotto
item['product_material']=materiale_prodotto
item['fabric_type']=tipo_di_tessuto
item['star_1']=star_1
item['star_2']=star_2
item['star_3']=star_3
item['star_4']=star_4
item['star_5']=star_5
# item['ratings_num'] = ratings_num
# item['reviews_num'] = reviews_num
item['scrap_time']=scrap_time
item['reviews_link']=reviews_link
item['size']=size
item['data_first_available']=data_first_available
rendimento elemento
Quando si raccoglie una quantità consistente di dati, cambiare l'IP e gestire il riconoscimento captcha.
4. Metodi per i middleware scaricatori
4.1 process_request(self, request, spider)
A. Richiamato quando ogni richiesta passa attraverso il middleware di download.
B. Restituire None: se non viene restituito alcun valore (o restituire esplicitamente None), l'oggetto richiesta viene passato al downloader o ad altri metodi process_request con peso inferiore.
C. Restituzione dell'oggetto Response: Non vengono effettuate altre richieste e la risposta viene restituita al motore.
D. Restituzione dell'oggetto Request: L'oggetto richiesta viene passato allo schedulatore attraverso il motore. Altri metodi process_request con peso inferiore vengono saltati.
4.2 process_response(self, request, response, spider)
A. Richiamato quando il downloader completa la richiesta HTTP e passa la risposta al motore.
B. Risposta di ritorno: Passata allo spider per l'elaborazione o al metodo process_response di altri middleware di download con un peso inferiore.
C. Restituzione dell'oggetto Request: Passato allo scheduler attraverso il motore per ulteriori richieste. Altri metodi process_request con peso inferiore vengono saltati.
D. Configurare l'attivazione del middleware e impostare i valori dei pesi in settings.py. I pesi più bassi sono prioritari.
middlewares.py
4.3 Impostazione dell'IP proxy
classe ProxyMiddleware(oggetto):
def process_request(self,request, spider):
request.meta['proxy'] = proxyServer
request.header["Proxy-Authorization"] = proxyAuth
def process_response(self, request, response, spider):
if response.status = '200':
request.dont_filter = True
restituire la richiesta
classe AmazonspiderDownloaderMiddleware:
# Non tutti i metodi devono essere definiti. Se un metodo non è definito,
# scrapy si comporta come se il middleware del downloader non modificasse gli oggetti
# oggetti passati.
@metodo di classe
def from_crawler(cls, crawler):
# Questo metodo è usato da Scrapy per creare gli spider.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
restituire s
def process_request(self, request, spider):
# USER_AGENTS_LIST: setting.py
user_agent = random.choice(USER_AGENTS_LIST)
request.headers['User-Agent'] = user_agent
cookies_str = 'il cookie incollato dal browser'.
# trasferimento di cookies_str a cookies_dict
cookies_dict = {i[:i.find('=')]: i[i.find('=') + 1:] for i in cookies_str.split('; ')}
request.cookies = cookies_dict
# print("---------------------------------------------------")
# print(request.headers)
# print("---------------------------------------------------")
restituire Nessuno
def process_response(self, request, response, spider):
restituisce la risposta
def process_exception(self, request, exception, spider):
pass
def spider_opened(self, spider):
spider.logger.info('Spider aperto: %s' % spider.name)
4.5 Ottenere Raschiamento Codice di verifica di Amazon per lo sblocco da Amazon.
def captcha_verfiy(nome_immagine):
# captcha_verfiy
reader = easyocr.Reader(['ch_sim', 'en'])
# reader = easyocr.Reader(['en'], detection='DB', recognition = 'Transformer')
risultato = reader.readtext(nome_immagine, dettaglio=0)[0]
# risultato = reader.readtext('https://www.somewebsite.com/chinese_tra.jpg')
se risultato:
risultato = risultato.replace(' ', '')
restituire il risultato
def download_captcha(captcha_url):
# scarica-captcha
response = requests.get(captcha_url, stream=True)
provare:
con open(r'./captcha.png', 'wb') come logFile:
per chunk in response:
logFile.write(chunk)
logFile.close()
print("Download effettuato!")
except Exception as e:
print("Errore nel log del download!")
classe AmazonspiderVerifyMiddleware:
@classmethod
def from_crawler(cls, crawler):
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
restituire s
def process_request(self, request, spider):
return None
def process_response(self, request, response, spider):
# print(response.url)
se 'Captcha' in response.text:
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, come Gecko) Chrome/109.0.0.0 Safari/537.36"
}
session = requests.session()
resp = session.get(url=response.url, headers=headers)
response1 = etree.HTML(resp.text)
captcha_url = "".join(response1.xpath('//div[@class="a-row a-text-center"]/img/@src'))
amzon = "".join(response1.xpath("//input[@nome='amzn']/@valore"))
amz_tr = "".join(response1.xpath("//input[@nome='amzn-r']/@valore"))
scaricare_captcha(captcha_url)
captcha_text = captcha_verfiy('captcha.png')
url_new = f "https://www.amazon.com/errors/validateCaptcha?amzn={amzon}&amzn-r={amz_tr}&field-keywords={captcha_text}"
resp = session.get(url=url_new, headers=headers)
if "Scusi, dobbiamo solo assicurarci che lei non sia un robot" not in str(resp.text):
response2 = HtmlResponse(url=url_new, headers=headers,body=resp.text, encoding='utf-8')
if "Scusi, dobbiamo solo assicurarci che lei non sia un robot" not in str(response2.text):
restituire response2
altrimenti:
restituire la richiesta
altro:
restituisce la risposta
def process_exception(self, request, exception, spider):
pass
def spider_opened(self, spider):
spider.logger.info('Spider aperto: %s' % spider.name)
Questo è tutto il codice relativo allo scraping dei dati di Amazon.
Se c'è bisogno di aiuto, per favore fatelo sapere a Supporto OkeyProxy sapere.
Fornitori di proxy consigliati: Okeyproxy - Top 5 Socks5 Proxy Provider con oltre 150 milioni di proxy residenziali da oltre 200 Paesi. Ottenete una prova gratuita di 1 GB di Proxy residenziali adesso!

