
In the realm of web scraping, proxies play a crucial role in ensuring smooth and uninterrupted data collection. When scraping large amounts of data from websites, it’s common to encounter IP blocks or rate limits. This is where proxy scraper proxies come in handy—they help bypass these restrictions and make scraping more efficient and anonymous.
This blog will explain what proxy scraper proxies are, why they’re essential for scraping, and how to utilize the right ones for your needs.
What Are Proxy Scrapers?
Proxy scrapers are specialized proxies used during web scraping. They act as intermediaries between your scraping tool and the target website, masking your real IP address. By rotating IP addresses, these proxies help avoid being detected or blocked by websites that have anti-scraping mechanisms in place.
- IP Rotation: Automatically switches IP addresses to avoid detection.
- Geo-Targeting: Allows selection of IPs from specific countries or regions.
- Anonimato elevato: Keeps your identity hidden while scraping.
- Velocità e affidabilità: Ensures smooth data collection without interruptions.
Why Is Proxy Scraper Important?
- Websites often block repeated requests from the same IP. Proxies distribute requests across multiple IPs, reducing the risk of detection.
- Proxy scraper proxies help handle rate limits by distributing traffic across various IPs.
- Use proxies to view region-specific content by masking your location.
- Avoid CAPTCHAs and blocks, ensuring smooth data collection.
Types of Proxies for Scraping
-
Deleghe residenziali:
Assigned by ISPs to real devices, highly anonymous, and best for strict websites.
-
Data Center Proxies:
Faster and cheaper, suitable for less-secure sites.
-
Proxy a rotazione:
Change IPs automatically for large-scale scraping.
-
Static Proxies:
Maintain the same IP address for session consistency.
How to Choose the Best Proxy Scraper
Follow these tips to select the right proxies for your needs:
1. Consider the Target Website
- Utilizzo deleghe residenziali for high-security websites.
- Proxy per centri dati work well for less-secure sites.
2. Look for Rotating Options
Rotating proxies reduce the risk of detection and IP bans.
3. Check Speed and Uptime
Ensure that the proxy scraper offers high speed and reliable uptime to avoid interruptions during scraping.
4. Geo-Targeting Capabilities
If you need data from specific regions, choose proxies that allow geo-targeting. (OkeyProxy offers 150M+ IPs from more than 200 countries and areas, supporting city targeting and ISP targeting.)
Recommended Proxy Providers for Scraping
For efficient and reliable web scraping, using a trusted proxy provider is essential. OkeyProxy is a great choice, offering:
- Proxy residenziali a rotazione: Perfect for bypassing IP bans and accessing region-specific content.
- High-Speed Data Center Proxies: Ideal for fast and large-scale scraping tasks.
- Copertura globale: Proxies from locations worldwide for geo-targeted scraping.

Steps to Use a Proxy Scraper
Using proxies is essential for web scraping to maintain anonymity, avoid IP bans, and bypass restrictions. Below are the detailed steps to effectively use a proxy for scraping:
Pre. Get Proxy Details
Different proxies are suitable for various scraping needs: Use a reliable provider, OkeyProxy, for high-quality proxy services and obtain IP address, port and more information from dashboard.


Servizio proxy Socks5/Http di prim'ordine
- Proxy residenziali a rotazione
- Static ISP Residential Proxies
- Proxy per data center
- More Custom Plans & Prices
Note: Avoid free proxies for scraping due to potential security risks and instability.
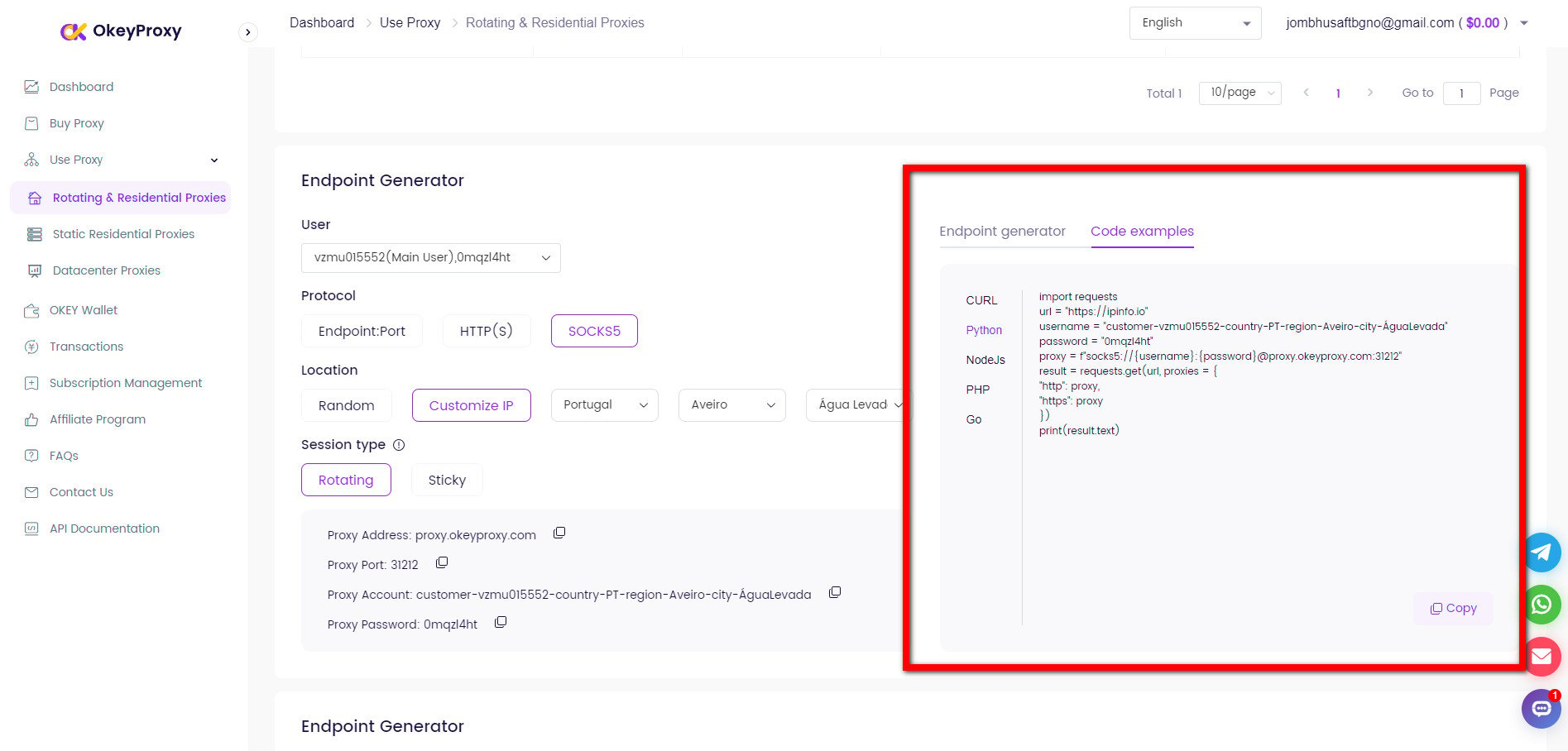
1. Browser-Based Scraping
For tools like Selenium:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--proxy-server=http://your-proxy-server:port')
driver = webdriver.Chrome(options=chrome_options)
driver.get('http://example.com')2. Command-Line Tools
For tools like cURL:
curl -x http://proxy-server:port http://example.com3. Libraries (e.g., Python’s requests)
Set the proxy in the richieste library from Pitone:
import requests
proxies = {
"http": "http://your-proxy-server:port",
"https": "http://your-proxy-server:port",
}
response = requests.get('http://example.com', proxies=proxies)
print(response.text)4. Authentication
If the proxy requires authentication, provide credentials:
proxies = {
"http": "http://username:password@proxy-server:port",
"https": "http://username:password@proxy-server:port",
}5. Handle Rotation/Rate Limits
For large-scale scraping:
- Utilizzo proxy rotanti a change IPs after each request.
- Incorporate delays between requests to mimic human behavior.
Example with richieste e time for delay:
import time
for url in url_list:
response = requests.get(url, proxies=proxies)
print(response.status_code)
time.sleep(2) # Delay between requestsConclusione
Proxy scrapers are essential for successful web scraping as they help bypass blocks, avoid detection, and ensure uninterrupted access to data. Whether you’re scraping for research, SEO, or business insights, investing in the right proxies will save you time and effort while boosting your efficiency.
Looking for a reliable proxy scraper to support your scraping needs? Consider the option of OkeyProxy, which offers high-speed, secure proxies perfect for web scraping tasks.





")


