
Scraping degli account utente su Instagram e TikTok comporta la raccolta di dati da queste piattaforme. È importante notare che lo scraping di queste piattaforme potrebbe violare i loro termini di servizio e potenzialmente portare a divieti di accesso o a conseguenze legali. Pertanto, utilizzare Proxy per ruotare l'indirizzo IP è un suggerimento necessario per il web scraping. Tenendo presente questo, ecco una guida passo passo per estrarre i dati degli utenti dall'interfaccia web di Instagram/TikTok!
Come raschiare gli account utente su IG e TikTok con Python
Vediamo come raschiare i dati del profilo degli utenti da Instagram e TikTok, compresi nome utente, nome completo, descrizione e immagine del profilo.

Passo 1: Impostazione dell'ambiente
- Installare Python e Pip: Assicurarsi che Python sia installato sul computer. È possibile scaricarlo da python.org. Pip, il programma di installazione dei pacchetti per Python, viene solitamente fornito con le installazioni di Python.
- Installare le librerie necessarie:
pip installa richieste beautifulsoup4 pandas selenium - Scaricare Webdriver: Per Selenium, è necessario scaricare il WebDriver appropriato per il proprio browser. Per Chrome, è possibile ottenere ChromeDriver da qui.
Passo 2: creare un raschietto per Instagram
A. Scraping di dati pubblici
Impostazione di base:
importare le richieste
da bs4 importa BeautifulSoup
importare pandas come pd
# Funzione per ottenere il contenuto HTML
def get_html(url):
response = requests.get(url)
restituire response.textEstrazione delle informazioni sull'utente:
def scrape_instagram_user(username):
url = f'https://www.instagram.com/{username}/'
html = get_html(url)
soup = BeautifulSoup(html, 'html.parser')
# Estrazione dei dati rilevanti
user_data = {}
user_data['username'] = username
user_data['full_name'] = soup.find('meta', {'property': 'og:title'})['content'].split('-')[0].strip()
user_data['description'] = soup.find('meta', {'property': 'og:description'})['content']
user_data['profile_image'] = soup.find('meta', {'property': 'og:image'})['content']
return user_data
# Esempio di utilizzo
utente = scrape_instagram_user('instagram')
print(utente)B. Gestire i contenuti dinamici con Selenium
Configurazione di Selenium:
da selenium import webdriver
da selenium.webdriver.chrome.service import Service as ChromeService
da selenium.webdriver.common.by import By
da selenium.webdriver.chrome.options import Options
importare tempo
# Impostazione del WebDriver
chrome_options = Options()
chrome_options.add_argument("--headless")
service = ChromeService(executable_path='/path/to/chromedriver')
driver = webdriver.Chrome(service=service, options=chrome_options)
# Funzione per ottenere contenuti dinamici
def get_dynamic_content(url):
driver.get(url)
time.sleep(3) # Attendere il caricamento della pagina
return driver.page_source
# Esempio di utilizzo
html = get_dynamic_content('https://www.instagram.com/instagram/')Passo 3: Creare uno scraper per TikTok
A. Scraping di dati pubblici
Impostazione di base:
def scrape_tiktok_user(username):
url = f'https://www.tiktok.com/@{username}'
html = get_html(url)
soup = BeautifulSoup(html, 'html.parser')
# Estrazione dei dati rilevanti
user_data = {}
user_data['username'] = username
user_data['full_name'] = soup.find('h1', {'data-e2e': 'user-title'}).text if soup.find('h1', {'data-e2e': 'user-title'}) else Nessuno
user_data['description'] = soup.find('h2', {'data-e2e': 'user-subtitle'}).text if soup.find('h2', {'data-e2e': 'user-subtitle'}) else None
user_data['profile_image'] = soup.find('img', {'class': 'avatar'})['src'] if soup.find('img', {'class': 'avatar'}) else None
restituire user_data
# Esempio di utilizzo
user = scrape_tiktok_user('tiktok')
print(utente)B. Gestire i contenuti dinamici con Selenium
Configurazione di Selenium:
# Riutilizzare l'impostazione di Selenium dalla sezione Instagram
# Esempio di utilizzo per TikTok
html = get_dynamic_content('https://www.tiktok.com/@tiktok')Passo 4: salvare i dati in CSV
Salvataggio dei dati:
def save_to_csv(data, filename='output.csv'):
df = pd.DataFrame(data)
df.to_csv(filename, index=False)
# Esempio di utilizzo
dati = [scrape_instagram_utente('instagram'), scrape_tiktok_utente('tiktok')]
save_to_csv(dati)Passo 5: Utilizzo dei proxy e gestione del limite di velocità
Utilizzando i proxy per scrapare Instagram e TikTok, come OkeyProxy, a proxy per lo scraping del webè essenziale per aggirare i limiti di velocità e di Divieti IP imposti dalla piattaforma, progettati per prevenire l'estrazione eccessiva di dati e mantenere l'integrità del servizio. I proxy consentono di distribuire le richieste di scraping su più indirizzi IP, riducendo la probabilità di essere segnalati come utenti sospetti e garantendo un accesso continuo ai dati necessari. Questo è particolarmente importante su piattaforme come TikTok, dove elevati volumi di richieste possono innescare difese automatiche che bloccano o limitano l'accesso. Sfruttando i proxy, è possibile mantenere un'operazione di scraping stabile ed efficiente, raccogliendo dati senza subire interruzioni significative.
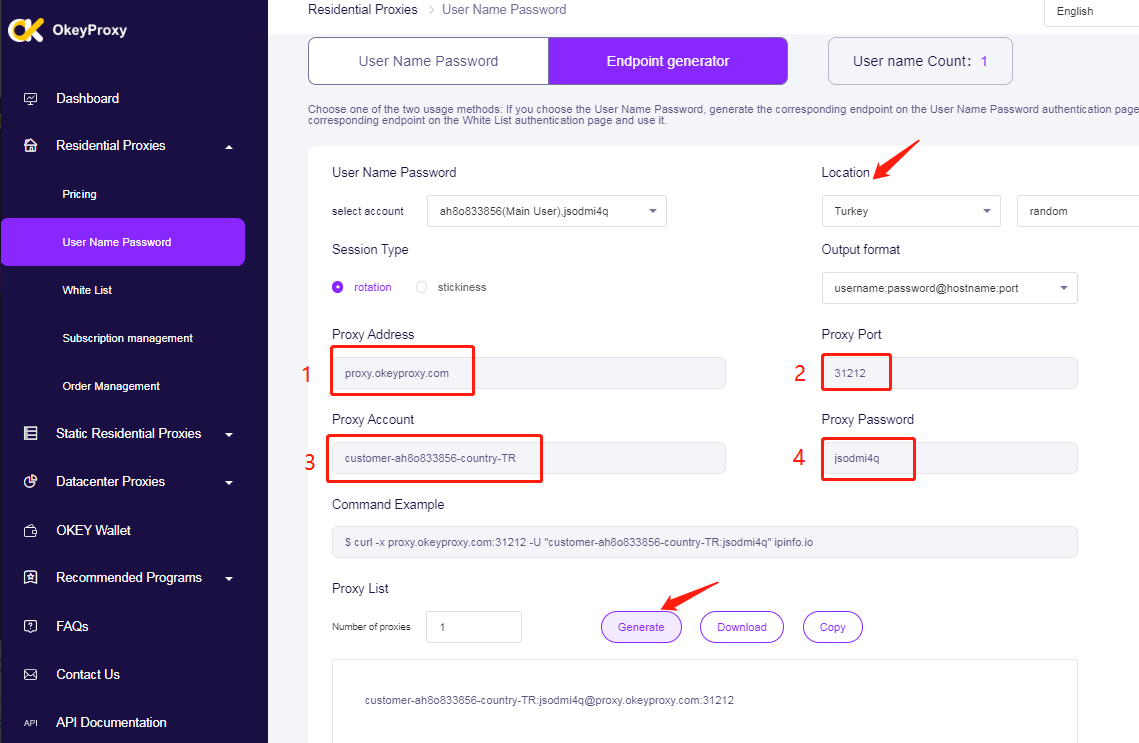
Impostazione dei proxy:
proxy = {
'http': 'http://your_proxy_here',
'https': 'https://your_proxy_here',
}
# Esempio di utilizzo con le richieste
response = requests.get(url, proxies=proxies)Gestione della limitazione della velocità:
tempo di importazione
# Funzione per aggiungere un ritardo
def delayed_request(url, delay=2):
time.sleep(delay)
return get_html(url)Esempio di caso di studio per lo scraping dei dati su Instagram e TikTok
Scenario
Siete incaricati di raccogliere i dati dei profili di alcuni utenti di Instagram e TikTok per analizzare la loro presenza sui social media per una campagna di marketing.
Passi
- Impostazione dell'ambiente: Assicurarsi che tutte le librerie necessarie siano installate e che WebDriver sia configurato.
- Raschiamento dei dati utente di Instagram:
instagram_usernames = ['instagram', 'cristiano', 'natgeo'] instagram_data = [] per username in instagram_usernames: user_data = scrape_instagram_user(username) instagram_data.append(user_data) save_to_csv(instagram_data, 'instagram_users.csv') - Raschiare i dati degli utenti di TikTok:
tiktok_usernames = ['tiktok', 'charlidamelio', 'therock'] tiktok_data = [] per username in tiktok_usernames: user_data = scrape_tiktok_user(username) tiktok_data.append(user_data) save_to_csv(tiktok_data, 'tiktok_users.csv') - Gestire i contenuti dinamici con Selenium: Utilizzare la configurazione di Selenium per recuperare l'origine della pagina e analizzare i dati per i profili con contenuto dinamico.
Altro modo: Raschiare gli account utente da Instagram/Tiktok con API
Utilizzare l'API Instagram
Instagram offre un'API che consente di accedere ai dati pubblici. Tuttavia, questa API è limitata e richiede l'approvazione, il che la rende meno flessibile per lo scraping su larga scala.
- Registrate un account per sviluppatori su Facebook for Developers.
- Creare un'applicazione di visualizzazione di base Instagram.
- Utilizzare gli endpoint API per accedere ai dati degli utenti, compresi i profili e i media.

Utilizzare l'API di TikTok
TikTok fornisce un'API pubblica per accedere ad alcuni dati degli utenti, ma come Instagram, ha delle limitazioni e richiede l'approvazione.
- Richiedete l'accesso all'API di TikTok tramite il portale degli sviluppatori.
- Utilizzare gli endpoint API per raccogliere i profili e i contenuti degli utenti.

Considerazioni sulla raschiatura degli account utente su Instagram/Tiktok
- Assicuratevi di avere il diritto di effettuare lo scraping dei dati e di rispettare i termini di servizio della piattaforma.
- Attuare ritardi e utilizzo corretti deleghe per evitare di essere bloccati.
- Gestire i dati raccolti in modo responsabile e rispettare la privacy degli utenti.
Sintesi
Questo è tutto. Seguendo questi passaggi per estrarre i dati tramite Python con Proxy o l'API originale della piattaforma, è possibile effettuare lo scraping degli account utente su Instagram e TikTok in modo efficace, rispettando le linee guida legali ed etiche.
