
Come potente strumento per l'estrazione di grandi quantità di dati da Internet, il web scraping ha rivoluzionato il modo in cui le aziende raccolgono e analizzano i dati, fornendo loro preziose informazioni che guidano i processi decisionali. Tuttavia, uno scraping web efficace richiede spesso l'uso di uno strumento specifico: un proxy di scraping.
In questo articolo, vedremo cos'è il proxy scarping, perché usare i proxy per il web scraping., tipi di proxy per lo scraping del web e come utilizzare i proxy per lo scraping del web.
Che cos'è un proxy di scraping?
Un proxy di scraping è un server che funge da intermediario tra un web scraper (il cliente) e il sito web da scrapare. Quando uno scraper invia una richiesta a un sito web, questa passa prima attraverso il server proxy, che poi inoltra la richiesta al sito web. Anche la risposta del sito web passa attraverso il proxy prima di raggiungere lo scraper. Lo scopo principale di un proxy di scraping è quello di mascherare l'indirizzo IP dello scraper, proteggendolo così dall'essere rilevato e bloccato dal sito web.
Perché utilizzare Proxy per lo scraping del web?
Ci sono alcuni motivi per cui l'uso di un proxy di scraping è essenziale per uno scraping web efficiente:
- Anonimato: Come accennato in precedenza, un proxy di scraping garantisce l'anonimato nascondendo il vero indirizzo IP dello scraper. L'anonimato è fondamentale perché i siti web spesso bloccano gli indirizzi IP che inviano un numero eccessivo di richieste in un breve periodo, sospettando che si tratti di bot.
- Superare le restrizioni geografiche: Alcuni siti web limitano l'accesso in base alla posizione geografica. Un proxy di scraping può aiutare a bypassare queste restrizioni instradando le richieste attraverso un server in una località consentita.
- Scraping parallelo: L'uso di più proxy consente lo scraping parallelo, ossia l'invio simultaneo di più richieste a un sito web. Questo approccio riduce significativamente il tempo necessario per effettuare lo scraping di grandi quantità di dati.
- Riduzione del rischio di essere bloccati: Ruotando tra diversi proxy, è possibile distribuire le richieste su più indirizzi IP, riducendo la probabilità che un singolo indirizzo IP venga bloccato.
Tipi di Web Proxy di scraping
Esistono diversi tipi di proxy per lo scraping del Web, tra cui:
- Proxy per data center: Sono il tipo più comune di proxy. Non sono affiliati agli ISP e sono invece forniti da un servizio di terze parti, che fornisce un indirizzo IP privato e anonimo. Se da un lato sono più veloci e convenienti dei proxy residenziali, dall'altro sono anche più facili da individuare e bloccare per i siti web. Inoltre, c'è un rischio maggiore di essere segnalati e inseriti nella lista nera di alcuni siti.
- Deleghe residenziali: These are IP addresses provided by Internet Service Providers (ISPs) to homeowners. They are highly anonymous and hard for websites to detect or block. They’re known to be more secure compared to proxy per centri dati and can be more expensive.
- Proxy a rotazione: Questi proxy cambiano automaticamente l'indirizzo IP che assegnano alle vostre richieste a intervalli regolari. Questa rotazione rende difficile per i siti web rilevare e bloccare le vostre attività di scraping.
- Proxy pubblici: I proxy pubblici sono gratuiti e sono una delle opzioni più accessibili. Per questo motivo sono spesso utilizzati da più utenti contemporaneamente. Tuttavia, hanno una velocità di connessione inferiore rispetto ai proxy privati, il che rende più difficile lo scraping del Web. Inoltre, i proxy pubblici sono inaffidabili e particolarmente suscettibili di crash e di virus e attacchi dannosi.
- Proxy anonimi: Proprio come dice il nome: mantiene la vostra identità anonima. Mentre un proxy pubblico non può garantire la riservatezza del vostro indirizzo IP, un proxy anonimo può farlo. Come i proxy pubblici, possono essere utilizzati da più utenti contemporaneamente. Tuttavia, l'utilizzo continuo dipende dal numero di utenti attuali. Gli spammer utilizzano spesso i proxy anonimi, il che può comportare il divieto di utilizzo dell'intero proxy per alcuni siti, poiché utilizza lo stesso indirizzo IP per tutti gli utenti.
- Proxy 4G: anche i proxy 4G sono tra i più affidabili grazie alla loro velocità e qualità, ma possono essere molto più costosi rispetto ad altri proxy. Ogni volta che un proxy 4G stabilisce una nuova connessione, l'operatore di rete assegna a ogni dispositivo un indirizzo IP nuovo di zecca, il che lo rende ideale per lo scraping del web, in quanto evita di essere inserito nella lista nera.
Come configurare i proxy per lo strumento di scraping web?
Per introdurlo, prendiamo come esempio Octoparse Scraper. Octoparse si distingue come potente strumento di scraping del web, rinomato per la sua interfaccia accessibile e le sue funzionalità complete. Il suo meccanismo "point-and-click" di facile utilizzo consente agli utenti di estrarre senza sforzo dati da siti web complessi, eliminando la necessità di competenze di codifica. Octoparse è in grado di soddisfare un'ampia gamma di attività di estrazione dei dati, vantando caratteristiche come modelli precostituiti, estrazione basata su cloud, integrazione API e scraping programmato per l'automazione. E vi mostreremo come configurare OkeyProxy con Octoparse in passi dettagliati.
Fase 1: Scarica Octoparse dal sito web ufficiale.
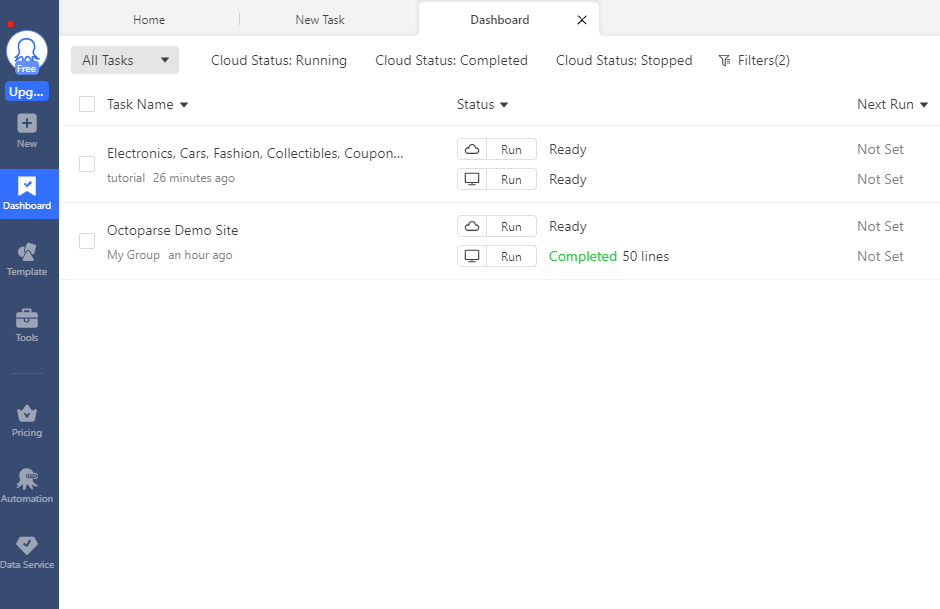
Fase 2: Aprire il client e visitare la dashboard del client, come mostrato nella seguente schermata.
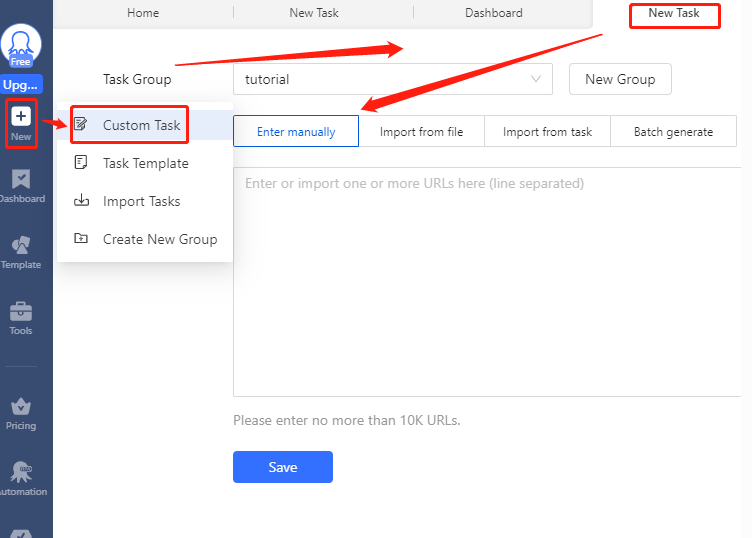
Fase 3: A questo punto, fare clic su "nuovo" e andare su "attività personalizzata" per creare una nuova attività.
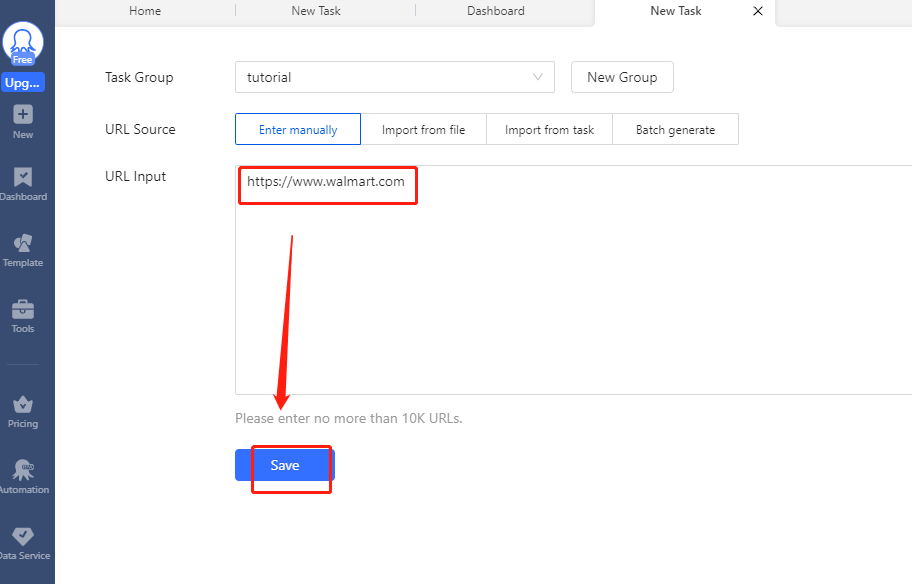
Passo 4: È possibile inserire l'URL di scraping e fare clic su "salva".
Passo 5: Individuare "Impostazioni attività" e fare clic su di essa.
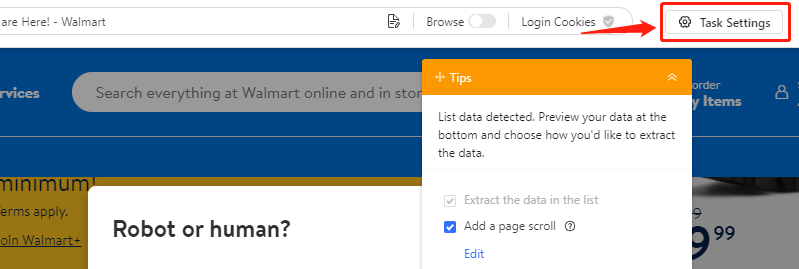
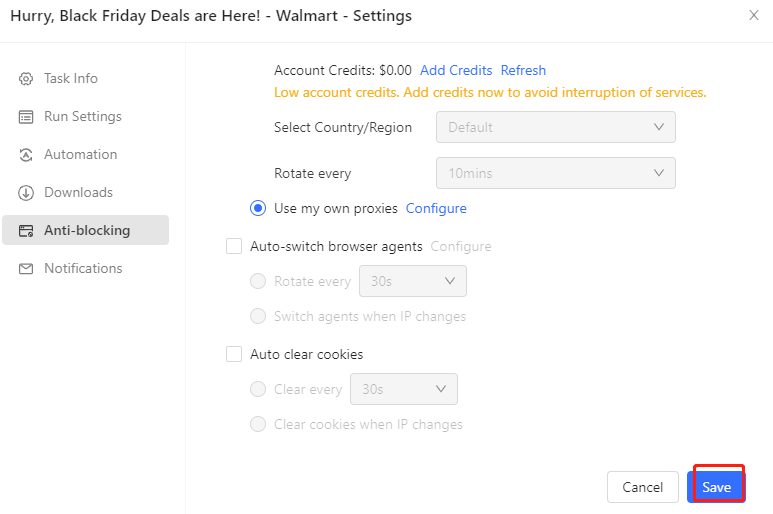
Passo 6: Entrate in "Anti-Blocking", quindi selezionate "Accesso ai siti web tramite proxy" > "Usa i miei proxy" > "Configura".
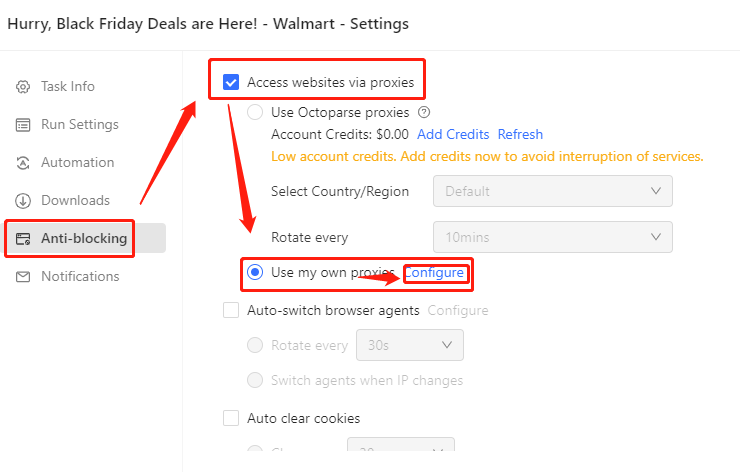
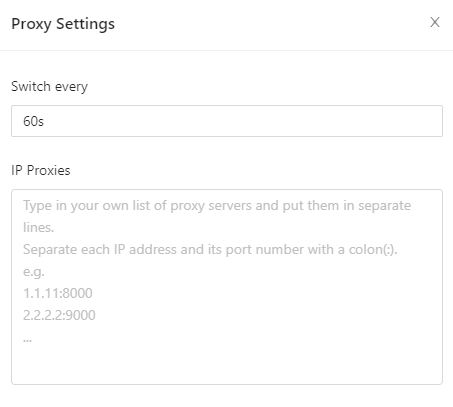
Passo 7: Ora è possibile impostare il proxy
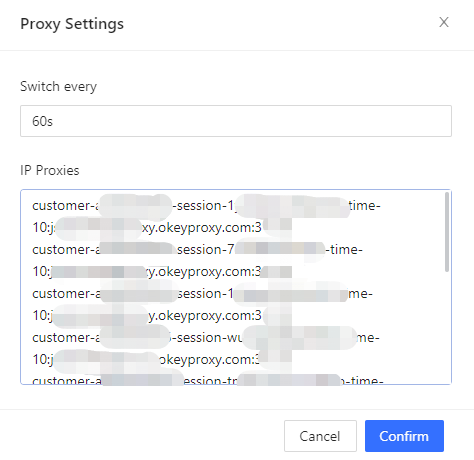
- Impostare il tempo di commutazione Da 1s a un numero illimitato di secondi. Il tempo predefinito è di 60 secondi.
- Ottenere i proxy IP da OkeyProxy.
Passo 8: Generare i proxy IP da Okeyproxy e poi copiarli, "proxy residenziali > Nome utente Password > Generatore di endpoint > Stickness > 10 (o più) > Genera".
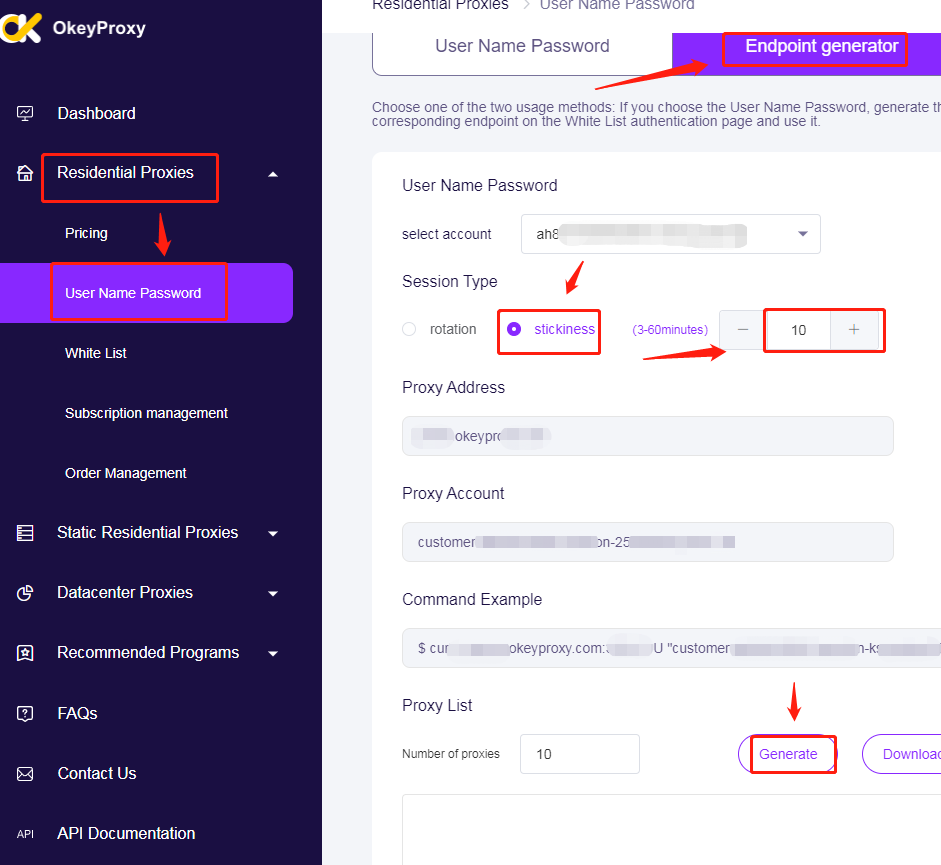
Passo 9: Ottenere 10 diversi IP di adesività dopo la generazione.

Passo 10: È necessario incollare gli IP in "IP proxy" nelle impostazioni del proxy di Octoparse.
Infine, salvare l'attività.
I migliori server proxy per lo scraping del web
1. OkeyProxy: OkeyProxy is the Top 5 Socks5 Proxies Provider with 150M+ Real Residential IPs and covers over 200 Countries. It’s committed to providing a full range of big data collection services for large/small/micro enterprises in all walks of life. It Supports almost all devices with Windows, IOS, Android, and Linux, and use cases of Antidetect Browser, Emulator, Scraper, etc. It is worth mentioning that you can use it conveniently, and there’s no cost for unavailable IP, the price is fair compared with other proxy servers. Besides, it provides a Prova gratuita di 1 GB di proxy per testare gratuitamente il prodotto.
2. ZenRows: ZenRows è uno strumento con un eccellente proxy avanzato per il web scraping. È anche uno strumento all-in-one in grado di gestire qualsiasi bypass anti-bot utilizzando proxy rotanti, anti-CAPTCHA e altro ancora con una sola chiamata API. L'API di ZenRows è dotata di proxy residenziali intelligenti che rendono difficile il rilevamento e l'inserimento nella blacklist di siti web e anti-bot.
Conclusione
I proxy di scraping sono uno strumento prezioso per qualsiasi operazione seria di scraping del Web. Forniscono l'anonimato necessario per eseguire lo scraping di dati senza essere individuati o bloccati, consentono di superare le restrizioni geografiche, permettono lo scraping parallelo e riducono il rischio di essere bloccati. Conoscendo i diversi tipi di proxy di scraping e i loro utilizzi, potrete scegliere quello più adatto alle vostre esigenze di scraping del web e migliorare significativamente l'efficienza e l'efficacia del vostro processo di estrazione dei dati.
Articolo correlato:
https://www.okeyproxy.com/en/blog/how-to-configure-okey-proxy-with-octoparse-scraper

