
Rastreo de cuentas de usuario en Instagram y TikTok implica recopilar datos de estas plataformas. Lo que es importante tener en cuenta es que el scraping de estas plataformas podría violar sus términos de servicio y potencialmente conducir a la prohibición de cuentas o consecuencias legales. Por lo tanto, utilice Proxy para rotar la dirección IP es un consejo necesario para el web scraping. Con esto en mente, ¡aquí tienes una guía paso a paso para extraer datos de usuario de la interfaz web de Instagram/TikTok!
Cómo raspar cuentas de usuario en IG y TikTok por Python
Veamos cómo extraer datos de perfil de usuario de Instagram y TikTok, incluidos el nombre de usuario, el nombre completo, la descripción y la imagen de perfil.

Paso 1: Configurar el entorno
- Instale Python y Pip: Asegúrese de que Python está instalado en su máquina. Puede descargarlo de python.org. Pip, el instalador de paquetes para Python, suele venir con las instalaciones de Python.
- Instale las bibliotecas necesarias:
pip install peticiones beautifulsoup4 pandas selenium - Descargar Webdriver: Para Selenium, necesitará descargar el WebDriver apropiado para su navegador. Para Chrome, puede obtener ChromeDriver de aquí.
Paso 2: Crear un Scraper para Instagram
A. Obtención de datos públicos
Configuración básica:
importar peticiones
from bs4 import BeautifulSoup
import pandas como pd
# Función para obtener contenido HTML
def obtener_html(url):
response = requests.get(url)
return respuesta.textoExtracción de información del usuario:
def scrape_instagram_user(nombre_usuario):
url = f'https://www.instagram.com/{username}/'
html = get_html(url)
soup = BeautifulSoup(html, 'html.parser')
# Extracción de datos relevantes
datos_usuario = {}
user_data['nombre_usuario'] = nombre_usuario
user_data['full_name'] = soup.find('meta', {'property': 'og:title'})['content'].split('-')[0].strip()
user_data['description'] = soup.find('meta', {'property': 'og:description'})['content']
user_data['profile_image'] = soup.find('meta', {'property': 'og:image'})['content']
return datos_usuario
# Ejemplo de uso
usuario = scrape_instagram_usuario('instagram')
print(usuario)B. Manejo de contenido dinámico con Selenium
Configurar Selenium:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service as ChromeService
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Opciones
importar tiempo
Configuración del WebDriver #
chrome_options = Opciones()
chrome_options.add_argument("--headless")
service = ChromeService(ruta_ejecutable='/ruta/hacia/chromedriver')
driver = webdriver.Chrome(service=service, options=chrome_options)
# Función para obtener contenido dinámico
def obtener_contenido_dinámico(url):
driver.get(url)
time.sleep(3) # Espera a que se cargue la página
return driver.fuente_página
# Ejemplo de uso
html = get_dynamic_content('https://www.instagram.com/instagram/')Paso 3: Crear un Scraper para TikTok
A. Obtención de datos públicos
Configuración básica:
def scrape_tiktok_user(nombre_usuario):
url = f'https://www.tiktok.com/@{nombredeusuario}'
html = get_html(url)
soup = BeautifulSoup(html, 'html.parser')
# Extracción de datos relevantes
datos_usuario = {}
user_data['nombre_usuario'] = nombre_usuario
user_data['full_name'] = soup.find('h1', {'data-e2e': 'user-title'}).text if soup.find('h1', {'data-e2e': 'user-title'}) else None
user_data['description'] = soup.find('h2', {'data-e2e': 'user-subtitle'}).text if soup.find('h2', {'data-e2e': 'user-subtitle'}) else None
user_data['profile_image'] = soup.find('img', {'class': 'avatar'})['src'] if soup.find('img', {'class': 'avatar'}) else None
return datos_usuario
# Ejemplo de uso
usuario = scrape_tiktok_user('tiktok')
print(usuario)B. Manejo de contenido dinámico con Selenium
Configurar Selenium:
# Reutilizar la configuración de Selenium de la sección de Instagram
# Ejemplo de uso para TikTok
html = get_dynamic_content('https://www.tiktok.com/@tiktok')Paso 4: Guardar datos en CSV
Guardar datos:
def guardar_a_csv(datos, nombre_archivo='salida.csv'):
df = pd.DataFrame(datos)
df.to_csv(nombrearchivo, index=False)
# Ejemplo de uso
data = [scrape_instagram_user('instagram'), scrape_tiktok_user('tiktok')]
save_to_csv(datos)Paso 5: Uso de proxies y gestión de la limitación de velocidad
El uso de proxies para raspar Instagram y TikTok, como OkeyProxy, a proxy para web scrapinges esencial para eludir los límites de tarifa y Prohibiciones de IP impuestas por la plataforma, que están diseñadas para evitar la extracción excesiva de datos y mantener la integridad de su servicio. Los proxies te permiten distribuir tus solicitudes de scraping entre varias direcciones IP, lo que reduce la probabilidad de ser señalado como usuario sospechoso y garantiza un acceso continuo a los datos que necesitas. Esto es especialmente importante en plataformas como TikTok, donde los grandes volúmenes de solicitudes pueden activar defensas automatizadas que bloqueen o limiten el acceso. Mediante el uso de proxies, puede mantener una operación de scraping estable y eficiente, recopilando datos sin sufrir interrupciones significativas.
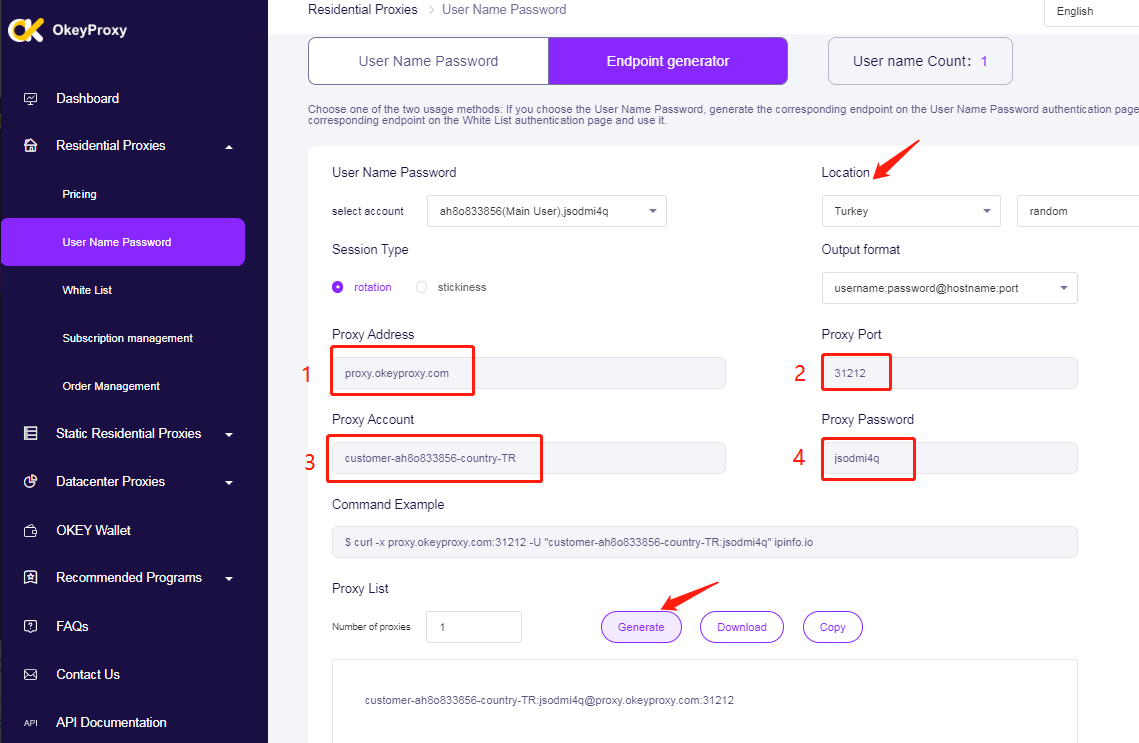
Configurar proxies:
proxies = {
'http': 'http://your_proxy_here',
'https': 'https://your_proxy_here',
}
# Ejemplo de uso con requests
response = requests.get(url, proxies=proxies)Tratamiento de la limitación de velocidad:
tiempo de importación
# Función para añadir retardo
def solicitud_retrasada(url, retraso=2):
time.sleep(delay)
return get_html(url)Ejemplo de caso práctico para raspar datos en Instagram y TikTok
Escenario
Te encargan que extraigas los datos de los perfiles de algunos usuarios de Instagram y TikTok para analizar su presencia en las redes sociales con vistas a una campaña de marketing.
Pasos
- Configurar entorno: Asegúrese de que todas las bibliotecas necesarias están instaladas y de que el WebDriver está configurado.
- Extraer datos de usuarios de Instagram:
instagram_usernames = ['instagram', 'cristiano', 'natgeo'] datos_instagram = [] for nombre_usuario in nombres_usuario_instagram: datos_usuario = scrape_instagram_user(nombre_usuario) instagram_data.append(datos_usuario) save_to_csv(datos_de_instagram, 'usuarios_de_instagram.csv') - Extraer datos de usuarios de TikTok:
tiktok_usernames = ['tiktok', 'charlidamelio', 'therock'] datos_tiktok = [] para nombre_usuario en nombres_usuario_tiktok: datos_usuario = scrape_tiktok_user(nombre_usuario) tiktok_data.append(datos_usuario) save_to_csv(tiktok_data, 'tiktok_users.csv') - Manejar contenido dinámico con Selenium: Utilice la configuración de Selenium para recuperar la fuente de la página y analizar los datos de los perfiles con contenido dinámico.
Otra Forma: Scrapear cuentas de usuario de Instagram/Tiktok con API
Utilizar la API de Instagram
Instagram ofrece una API que proporciona acceso a datos públicos. Sin embargo, esta API es limitada y requiere aprobación, lo que la hace menos flexible para el scraping a gran escala.
- Regístrate para obtener una cuenta de desarrollador en Facebook para desarrolladores.
- Crear una aplicación de visualización básica de Instagram.
- Utilice los puntos finales de la API para acceder a los datos de los usuarios, incluidos sus perfiles y medios.

Utiliza la API de TikTok
TikTok proporciona una API pública para acceder a algunos datos de los usuarios, pero al igual que Instagram, tiene limitaciones y requiere aprobación.
- Solicita acceso a la API de TikTok a través de su portal para desarrolladores.
- Utilice los puntos finales de la API para recopilar perfiles y contenidos de los usuarios.

Consideraciones para raspar cuentas de usuario en Instagram/Tiktok
- Asegúrese de que tiene derecho a extraer los datos y de que cumple las condiciones de servicio de la plataforma.
- Aplicar retrasos y uso adecuados apoderados para evitar ser bloqueado.
- Gestione los datos obtenidos de forma responsable y respete la privacidad de los usuarios.
Resumen
Eso es todo. Siguiendo estos pasos para extraer datos a través de Python con Proxy o la API original de la plataforma, puedes hacer scraping de cuentas de usuario en Instagram y TikTok de manera efectiva mientras cumples con las directrices legales y éticas.






