
Los datos son la piedra angular del análisis competitivo, la investigación de mercado y la estrategia empresarial. Una de las fuentes de datos más valiosas para las empresas de comercio electrónico es Amazon, el mayor mercado en línea del mundo. El rastreo de los productos de un vendedor en Amazon puede proporcionar información sobre estrategias de precios, ofertas de productos y opiniones de clientes, que son cruciales para tomar decisiones empresariales con conocimiento de causa.
Este artículo profundiza en el proceso de scraping de los productos de un vendedor en Amazon, cubriendo las herramientas esenciales, técnicas y mejores prácticas, al tiempo que aborda las consideraciones legales y éticas.
¿Incluye la estructura de datos de Amazon?
El sitio web de Amazon está estructurado de forma que categoriza los productos, las reseñas, los precios y otros detalles. Para raspar datos de productos con eficacia, es crucial comprender los siguientes componentes:
- Listados de productos: Contiene detalles como nombre del producto, descripción, precio e imágenes.
- Información del vendedor: Incluye valoraciones del vendedor, número de productos y nombre del vendedor.
- Opiniones y valoraciones: Proporciona opiniones de clientes y valoraciones de productos.
- Categorías de productos: Ayuda a filtrar y organizar los productos.
Raspar los productos de un vendedor en Amazon paso a paso
El scraping de los productos de un vendedor en Amazon requiere un enfoque detallado y estructurado, especialmente debido a las sofisticadas medidas anti-scraping de Amazon. A continuación se ofrece un tutorial completo que abarca varios aspectos del proceso, desde la configuración del entorno hasta la resolución de problemas como los CAPTCHA y el contenido dinámico.
1. Preparación del Web Scraping
Antes de sumergirse en el proceso de scraping, asegúrese de que su entorno está configurado con las herramientas y bibliotecas necesarias.
a. Herramientas y bibliotecas
- Python: Preferida por su rico ecosistema de bibliotecas.
- Bibliotecas:
solicita: Para realizar peticiones HTTP.BeautifulSoup: Para analizar el contenido HTML.Selenio: Para gestionar contenidos dinámicos e interacciones.Pandas: Para la manipulación y almacenamiento de datos.Chatarra: Si prefiere un enfoque de raspado más escalable y basado en arañas.
- Gestión de poderes:
peticiones-ip-rotator: Una biblioteca para rotar direcciones IP.- Servicios proxy como
OkeyProxypara los proxies rotatorios.
- Solucionadores CAPTCHA:
- Servicios como
2CaptchaoAnti-Captchapara resolver CAPTCHAs.
- Servicios como
b. Configuración del entorno
- Instale Python (si no está ya instalado).
- Configurar un entorno virtual:
python3 -m venv amazon-scraper source amazon-scraper/bin/activate - Instale las bibliotecas necesarias:
pip install peticiones beautifulsoup4 selenium pandas scrapy
2. Comprender los mecanismos antiscraping de Amazon
Amazon emplea varias técnicas para evitar el scraping automatizado, que suponen un reto para la recopilación de datos:
- Limitación de velocidad: Amazon limita el número de solicitudes que puedes hacer en un periodo corto.
- Bloqueo de IP: Las solicitudes frecuentes desde una misma IP pueden dar lugar a prohibiciones temporales o permanentes.
- CAPTCHAs: Se presentan para verificar si el usuario es humano.
- Contenido basado en JavaScript: Algunos contenidos se cargan dinámicamente mediante JavaScript, lo que requiere un tratamiento especial.
3. Localización de los productos del vendedor
a. Identificación del vendedor
Para rastrear los productos de un vendedor concreto, primero debe identificar el identificador único del vendedor o la URL de su tienda. La URL suele tener este formato:
https://www.amazon.com/s?me=SELLER_IDPuede encontrar esta URL visitando el escaparate del vendedor en Amazon.
b. Obtener listados de productos
Con el ID o la URL del vendedor, puede empezar a obtener los listados de productos. Dado que las páginas de Amazon suelen estar paginadas, tendrás que gestionar la paginación para asegurarte de que se extraen todos los productos.
importar peticiones
from bs4 import BeautifulSoup
seller_url = "https://www.amazon.com/s?me=SELLER_ID"
cabeceras = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, como Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
def get_products(vendedor_url):
productos = []
while vendedor_url:
response = requests.get(vendedor_url, cabeceras=cabeceras)
soup = BeautifulSoup(response.content, "html.parser")
# Extraer los detalles del producto
for producto in soup.select(".s-título-instrucciones-estilo"):
title = product.get_text(strip=True)
products.append(título)
# Encontrar la URL de la página siguiente
siguiente_página = soup.select_one("li.a-última a")
seller_url = f "https://www.amazon.com{next_page['href']}" if next_page else None
devolver productos
productos = get_products(vendedor_url)
print(productos)4. Manejo de la paginación
Las páginas de productos de Amazon suelen estar paginadas, lo que requiere un bucle para recorrer cada página. La lógica para esto se incluye en el obtener_productos donde comprueba la presencia de un botón "Siguiente" y extrae la URL de la página siguiente.
5. Manejo de contenidos dinámicos
Algunos detalles del producto, como el precio o la disponibilidad, pueden cargarse dinámicamente mediante JavaScript. En tales casos, tendrá que utilizar Selenio o un navegador sin cabeza como Dramaturgo para renderizar la página antes del scraping.
Uso de Selenium para contenido dinámico
from selenium import webdriver
from selenium.webdriver.chrome.service import Servicio
from selenium.webdriver.chrome.options import Opciones
from bs4 import BeautifulSoup
# Configurar las opciones de Chrome
chrome_options = Opciones()
chrome_options.add_argument("--headless") # Ejecutar en modo headless
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
# Iniciar el controlador de Chrome
service = Servicio('/ruta/a/chromedriver')
driver = webdriver.Chrome(service=service, options=chrome_options)
# Abrir la página del vendedor
driver.get("https://www.amazon.com/s?me=SELLER_ID")
# Esperar a que la página se cargue completamente
driver.implicitly_wait(5)
# Analiza el código fuente de la página con BeautifulSoup
soup = BeautifulSoup(driver.fuente_página, "html.parser")
# Extrae los detalles del producto
for producto in soup.select(".s-título-instrucciones-estilo"):
title = producto.get_text(strip=True)
print(título)
driver.quit()6. Tratar con CAPTCHAs
Amazon puede presentar CAPTCHAs para bloquear intentos de scraping. Si encuentra un CAPTCHA, tendrá que resolverlo manualmente o utilizar un servicio como 2Captcha para automatizar el proceso.
Ejemplo de uso de 2Captcha
solicitudes de importación
captcha_solution = solve_captcha("captcha_image_url") # Utilizar un servicio de resolución de CAPTCHA como 2Captcha
# Envía la solución con tu solicitud
datos = {
'field-keywords': 'your_search_term',
'captcha': captcha_solution
}
response = requests.post("https://www.amazon.com/s", data=datos, headers=cabeceras)7. Gestión de poderes
El rastreo de los productos de un vendedor en Amazon es un caso de uso común para los proxies, especialmente para las empresas dedicadas a la inteligencia de precios, el seguimiento de la competencia o la investigación de productos. Dado que Amazon emplea fuertes medidas anti-bot, proxies para el raspado de datos son esenciales para evitar la detección de Amazon.
Para evitar el bloqueo de IP, es crucial utilizar proxies rotatorios. Esto se puede conseguir utilizando una herramienta o servicio de gestión de proxies.
Configuración de proxies con peticiones
proxies = {
"http": "http://username:password@proxy_server:puerto",
"https": "https://username:password@proxy_server:port",
}
response = requests.get(seller_url, headers=headers, proxies=proxies)Rotar dirección IP con OkeyProxy
OkeyProxy es un proveedor de proxy ideal respaldado por tecnología patentada, que proporciona más de 150 millones de IPs residenciales rotativas reales y conformes, conectándose rápidamente a sitios web objetivo en cualquier país/región y eludiendo fácilmente bloqueos y prohibiciones de IP.
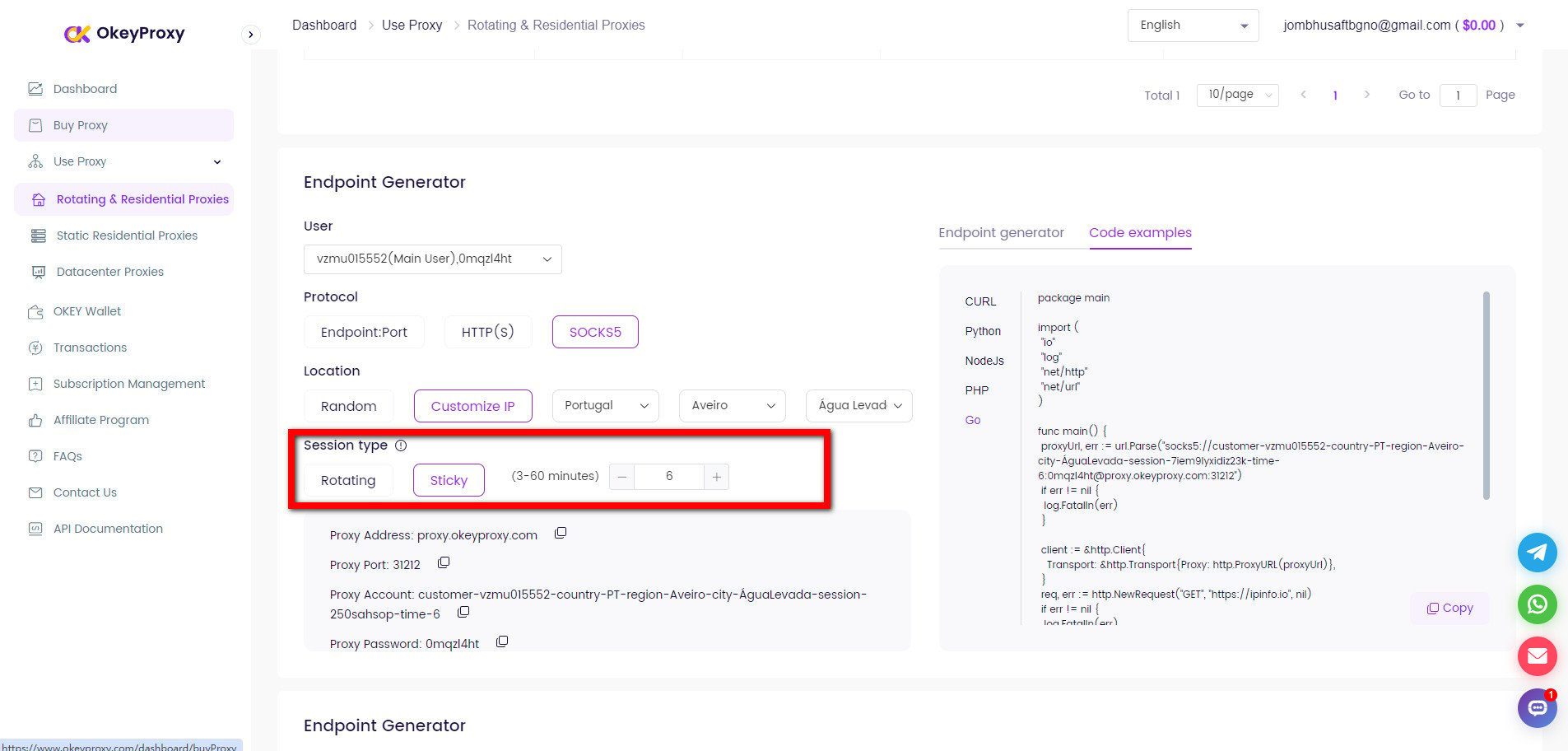
8. Almacenamiento de datos
Una vez obtenidos los datos, almacénelos en un formato estructurado. Pandas es una herramienta excelente para ello.
Guardar en CSV con Pandas
importar pandas como pd
# Asumiendo que products es una lista de diccionarios
df = pd.DataFrame(productos)
df.to_csv("amazon_products.csv", index=False)9. Mejores prácticas y retos
- Respetar robots.txt: Siga siempre las directrices especificadas en la página web de Amazon
robots.txtarchivo. - Limitación de velocidad: Implemente estrategias de limitación de velocidad para evitar la sobrecarga de los servidores de Amazon.
- Tratamiento de errores: Prepárese para gestionar diversos errores, incluidos los tiempos de espera de las solicitudes, los CAPTCHA y los errores de página no encontrada.
- Pruebas: Pruebe su rascador a fondo en un entorno controlado antes de utilizarlo a escala.
- Legalidad: Asegúrese de que sus actividades de scraping cumplen la normativa legal y las condiciones de servicio de Amazon.
10. Ampliación del proceso de raspado
Para operaciones de scraping a gran escala, considere la posibilidad de utilizar un marco como Chatarra o desplegando su scraper en una plataforma en la nube con capacidades de rastreo distribuido.
Otro método para raspar productos de vendedores de Amazon
Amazon proporciona API como la API de publicidad de productos para acceder a la información de los productos. Aunque este método es legítimo y cuenta con el apoyo de Amazon, requiere la aprobación de acceso a la API y tiene un alcance limitado.
-
Pros:
Con apoyo oficial, fiable.
-
Contras:
Acceso limitado, requiere aprobación y puede implicar costes de uso.
Preguntas frecuentes sobre el scraping de datos de Amazon
P1: ¿Es legal extraer datos de productos de Amazon?
R: Hacer scraping de Amazon sin permiso puede violar sus condiciones de servicio y podría acarrear consecuencias legales o el bloqueo de direcciones IP. Consulta siempre con un asesor legal antes de proceder.
P2: ¿Cómo evitar el bloqueo durante el scraping de Amazon?
R: Utilizar proxies para rotar la IP, respetar robots.txt, implementar retardos entre peticiones, evitar hacer scraping con demasiada frecuencia, etc., algunas medidas podrían minimizar el riesgo de ser bloqueado por Amazon.
P3: ¿Por qué deja de funcionar mi script de scraping?
R: Comprueba si Amazon ha cambiado la estructura de su sitio web o ha implementado nuevas medidas anti-scraping y ajusta el script para adaptarlo a los cambios. Además, comprueba y mantén el script con regularidad para garantizar su funcionalidad.
Resumen
El scraping de los productos de un vendedor en Amazon implica identificar la URL única del vendedor, navegar a través de listados de productos paginados y manejar contenido dinámico con herramientas como Selenium. Debido a las medidas anti-scraping de Amazon, como los CAPTCHA y la limitación de la tasa, es esencial utilizar proxies rotativos y considerar el cumplimiento de sus condiciones de servicio. El uso de bibliotecas como BeautifulSoup para contenidos estáticos y Selenium para contenidos dinámicos, junto con una gestión cuidadosa de las direcciones IP y los límites de velocidad, puede ayudar a extraer y almacenar eficazmente los datos de los productos, minimizando al mismo tiempo el riesgo de ser bloqueado.