
Im Bereich des Web Scraping spielen Proxys eine entscheidende Rolle bei der Gewährleistung einer reibungslosen und ununterbrochenen Datenerfassung. Beim Scraping großer Datenmengen von Websites stößt man häufig auf IP-Sperren oder Ratenbeschränkungen. Hier kommen Proxy Scraper Proxys ins Spiel - sie helfen dabei, diese Beschränkungen zu umgehen und machen das Scraping effizienter und anonymer.
In diesem Blog wird erklärt, was Proxy Scraper Proxys sind, warum sie für Scraping unerlässlich sind und wie Sie die richtigen für Ihre Bedürfnisse einsetzen.
Was sind Proxy Scraper?
Proxy-Scraper sind spezielle Proxys, die beim Web-Scraping eingesetzt werden. Sie fungieren als Vermittler zwischen Ihrem Scraping-Tool und der Ziel-Website und verschleiern Ihre echte IP-Adresse. Unter rotierende IP-AdressenDiese Proxys helfen dabei, zu vermeiden, dass sie von Websites, die über Anti-Scraping-Mechanismen verfügen, entdeckt oder blockiert werden.
- IP-Rotation: Wechselt automatisch die IP-Adresse, um eine Entdeckung zu vermeiden.
- Geo-Targeting: Ermöglicht die Auswahl von IPs aus bestimmten Ländern oder Regionen.
- Hohe Anonymität: Ihre Identität bleibt während des Scannens verborgen.
- Geschwindigkeit und Verlässlichkeit: Gewährleistet eine reibungslose Datenerfassung ohne Unterbrechungen.
Warum ist Proxy Scraper wichtig?
- Websites blockieren oft wiederholte Anfragen von der gleichen IP. Proxys verteilen die Anfragen auf mehrere IPs und verringern so das Risiko einer Entdeckung.
- Proxy-Scraper-Proxys helfen bei der Handhabung von Ratenbeschränkungen, indem sie den Datenverkehr auf verschiedene IPs verteilen.
- Verwenden Sie Proxys, um regionalspezifische Inhalte anzuzeigen, indem Sie Ihren Standort verbergen.
- Vermeiden Sie CAPTCHAs und Blöcke, um eine reibungslose Datenerfassung zu gewährleisten.
Arten von Proxys für Scraping
-
Vollmachten für Wohnzwecke:
Von Internetdienstleistern echten Geräten zugewiesen, hochgradig anonym und am besten für strenge Websites geeignet.
-
Rechenzentrum-Proxys:
Schneller und billiger, geeignet für weniger sichere Standorte.
-
Rotierende Proxys:
Ändern Sie IPs automatisch für großflächiges Scraping.
-
Statische Proxys:
Behalten Sie die gleiche IP-Adresse bei, um die Konsistenz der Sitzung zu gewährleisten.
Wie man den besten Proxy Scraper auswählt
Befolgen Sie diese Tipps, um die richtigen Proxys für Ihre Bedürfnisse auszuwählen:
1. Betrachten Sie die Ziel-Website
- Verwenden Sie Wohnsitzvollmachten für hochsichere Websites.
- Proxys für Rechenzentren eignen sich gut für weniger sichere Websites.
2. Suchen Sie nach rotierenden Optionen
Rotierende Proxys verringern das Risiko der Entdeckung und IP-Sperren.
3. Geschwindigkeit und Betriebszeit prüfen
Vergewissern Sie sich, dass der Proxy Scraper eine hohe Geschwindigkeit und eine zuverlässige Betriebszeit bietet, um Unterbrechungen beim Scrapen zu vermeiden.
4. Geo-Targeting-Fähigkeiten
Wenn Sie Daten aus bestimmten Regionen benötigen, wählen Sie Proxys, die Geotargeting ermöglichen. (OkeyProxy bietet mehr als 150 Mio. IPs aus mehr als 200 Ländern und Regionen, unterstützt Städte-Targeting und ISP Targeting).
Empfohlene Proxy-Anbieter für Scraping
Für effizientes und zuverlässiges Web Scraping ist die Verwendung eines vertrauenswürdigen Proxy-Anbieters unerlässlich. OkeyProxy ist eine gute Wahl und bietet:
- Rotierende Wohnsitzvollmachten: Perfekt für die Umgehung von IP-Sperren und den Zugriff auf regionsspezifische Inhalte.
- Hochgeschwindigkeits-Proxys für Rechenzentren: Ideal für schnelle und großflächige Schabearbeiten.
- Globale Abdeckung: Proxys von Standorten auf der ganzen Welt für geografisch gezieltes Scraping.

Schritte zur Verwendung eines Proxy Scrapers
Die Verwendung von Proxys ist für Web-Scraping unerlässlich, um die Anonymität zu wahren, IP-Sperren zu vermeiden und Einschränkungen zu umgehen. Nachfolgend finden Sie die detaillierten Schritte zur effektiven Verwendung eines Proxys für Scraping:
Vor. Details zur Vollmacht erhalten
Verschiedene Proxys eignen sich für unterschiedliche Scraping-Anforderungen: Verwenden Sie einen zuverlässigen Anbieter, OkeyProxyfür hochwertige Proxy-Dienste und erhalten IP-Adresse, Port und weitere Informationen aus dem Dashboard.


Erstklassiger Socks5/Http(s) Proxy-Dienst
- Rotating Residential Proxies
- Static ISP Residential Proxies
- Datacenter Proxies
- More Custom Plans & Prices
Hinweis: Vermeiden Sie kostenlose Proxys für das Scraping wegen möglicher Sicherheitsrisiken und Instabilität.
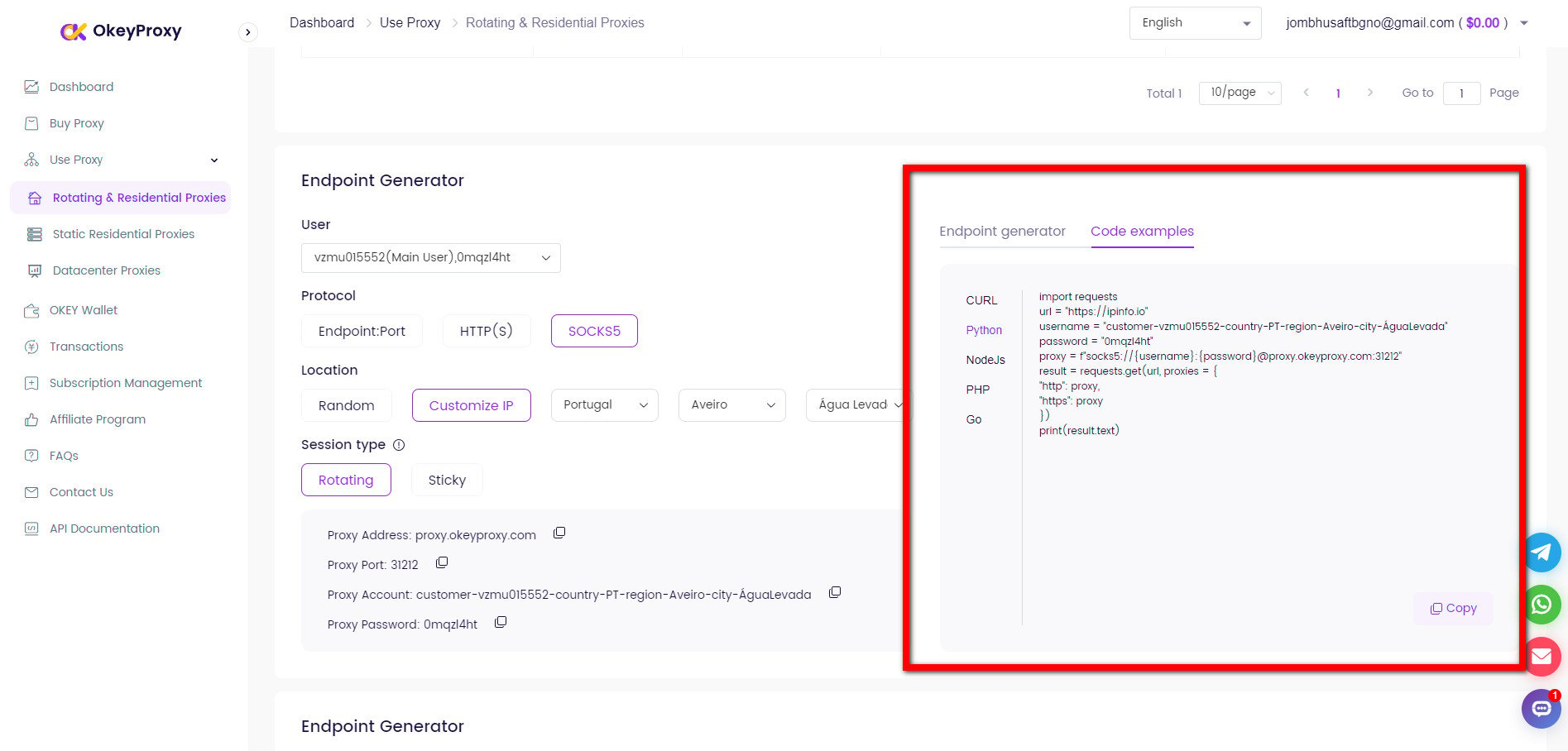
1. Browser-basiertes Scraping
Für Werkzeuge wie Selenium:
von selenium import webdriver
von selenium.webdriver.chrome.options importieren Optionen
chrome_options = Optionen()
chrome_options.add_argument('--proxy-server=http://your-proxy-server:port')
driver = webdriver.Chrome(options=chrome_options)
driver.get('http://example.com')2. Befehlszeilen-Tools
Für Werkzeuge wie cURL:
curl -x http://proxy-server:port http://example.com3. Bibliotheken (z. B. Python-Anfragen)
Setzen Sie den Proxy in der Anfragen Bibliothek von Python:
Einfuhranträge
proxies = {
"http": "http://your-proxy-server:port",
"https": "http://your-proxy-server:port",
}
response = requests.get('http://example.com', proxies=proxies)
print(antwort.text)4. Authentifizierung
Wenn der Proxy eine Authentifizierung erfordert, geben Sie die Anmeldedaten an:
proxies = {
"http": "http://username:password@proxy-server:port",
"https": "http://username:password@proxy-server:port",
}5. Grenzwerte für Drehung und Geschwindigkeit des Griffs
Für großflächiges Schaben:
- Verwenden Sie Drehbevollmächtigte zu IPs ändern nach jeder Anfrage.
- Bauen Sie Verzögerungen zwischen Anfragen ein, um menschliches Verhalten zu imitieren.
Beispiel mit Anfragen und Zeit für Verzögerungen:
Einfuhrzeit
for url in url_list:
response = requests.get(url, proxies=proxies)
print(antwort.status_code)
time.sleep(2) # Verzögerung zwischen AnfragenSchlussfolgerung
Proxy-Scraper sind für erfolgreiches Web-Scraping unverzichtbar, da sie dabei helfen, Sperren zu umgehen, eine Erkennung zu vermeiden und einen ununterbrochenen Zugriff auf Daten zu gewährleisten. Ganz gleich, ob Sie zu Forschungszwecken, zur Suchmaschinenoptimierung oder zur Gewinnung von Geschäftseinblicken Scrapen, die Investition in die richtigen Proxys spart Ihnen Zeit und Mühe und steigert Ihre Effizienz.
Suchen Sie nach einem zuverlässigen Proxy Scraper für Ihre Scraping-Anforderungen? Erwägen Sie die Option von OkeyProxydie sichere Hochgeschwindigkeits-Proxys bietet, die sich perfekt für Web-Scraping-Aufgaben eignen.