
Daten sind der Eckpfeiler der Wettbewerbsanalyse, der Marktforschung und der Unternehmensstrategie. Eine der wertvollsten Datenquellen für E-Commerce-Unternehmen ist Amazon, der größte Online-Marktplatz der Welt. Das Scraping der Produkte eines Verkäufers auf Amazon kann Einblicke in Preisstrategien, Produktangebote und Kundenrezensionen geben, die für fundierte Geschäftsentscheidungen entscheidend sind.
Dieser Artikel befasst sich mit dem Prozess des Scrappings von Produkten eines Verkäufers auf Amazon und geht dabei auf wichtige Tools, Techniken und bewährte Praktiken sowie auf rechtliche und ethische Aspekte ein.
Amazons Datenstruktur einschließen?
Die Website von Amazon ist so strukturiert, dass Produkte, Bewertungen, Preise und andere Details kategorisiert werden. Um Produktdaten effektiv zu scrapen, ist es wichtig, die folgenden Komponenten zu verstehen:
- Produktauflistungen: Enthält Details wie Produktname, Beschreibung, Preis und Bilder.
- Verkäufer-Informationen: Enthält Verkäuferbewertungen, Anzahl der Produkte und Verkäufername.
- Rezensionen und Bewertungen: Hier finden Sie Kundenfeedback und Produktbewertungen.
- Produktkategorien: Hilft beim Filtern und Organisieren von Produkten.
Scrapen Sie die Produkte eines Verkäufers auf Amazon Schritt für Schritt
Das Scraping der Produkte eines Verkäufers auf Amazon erfordert einen detaillierten und strukturierten Ansatz, insbesondere aufgrund der ausgefeilten Anti-Scraping-Maßnahmen von Amazon. Im Folgenden finden Sie eine umfassende Anleitung, die verschiedene Aspekte des Prozesses abdeckt, von der Einrichtung der Umgebung bis zum Umgang mit Herausforderungen wie CAPTCHAs und dynamischen Inhalten.
1. Vorbereitung von Web Scraping
Bevor Sie mit dem Scraping beginnen, sollten Sie sicherstellen, dass Ihre Umgebung mit den erforderlichen Tools und Bibliotheken ausgestattet ist.
a. Werkzeuge und Bibliotheken
- Python: Bevorzugt für sein reiches Ökosystem an Bibliotheken.
- Bibliotheken:
Anfragen: Zur Durchführung von HTTP-Anfragen.BeautifulSoup: Zum Parsen von HTML-Inhalten.Selen: Für den Umgang mit dynamischen Inhalten und Interaktionen.Pandas: Für die Bearbeitung und Speicherung von Daten.Scrapy: Wenn Sie ein skalierbareres, spiderbasiertes Scraping-Verfahren bevorzugen.
- Verwaltung von Vollmachten:
anfragen-ip-rotator: Eine Bibliothek zum Rotieren von IP-Adressen.- Proxy-Dienste wie
OkeyProxyfür rotierende Proxys.
- CAPTCHA-Löser:
- Dienste wie
2CaptchaoderAnti-Captchazum Lösen von CAPTCHAs.
- Dienste wie
b. Einrichtung der Umgebung
- Installieren Sie Python (falls nicht bereits installiert).
- Richten Sie eine virtuelle Umgebung ein:
python3 -m venv amazon-scraper Quelle amazon-scraper/bin/activate - Installieren Sie die erforderlichen Bibliotheken:
pip install anfragen beautifulsoup4 selenium pandas scrapy
2. Verständnis der Anti-Scraping-Mechanismen von Amazon
Amazon setzt verschiedene Techniken ein, um automatisiertes Scraping zu verhindern, was für Datensammlungen eine Herausforderung darstellt:
- Ratenbegrenzung: Amazon begrenzt die Anzahl der Anfragen, die Sie innerhalb eines kurzen Zeitraums stellen können.
- IP-Blockierung: Häufige Anfragen von einer einzigen IP können zu vorübergehenden oder dauerhaften Sperren führen.
- CAPTCHAs: Diese werden angezeigt, um zu überprüfen, ob der Benutzer ein Mensch ist.
- JavaScript-basierte Inhalte: Einige Inhalte werden dynamisch über JavaScript geladen, was eine besondere Handhabung erfordert.
3. Auffinden der Produkte des Verkäufers
a. Identifizieren Sie die Verkäufer-ID
Um die Produkte eines bestimmten Verkäufers abzurufen, müssen Sie zunächst die eindeutige ID des Verkäufers oder seine Schaufenster-URL ermitteln. Die URL hat in der Regel dieses Format:
https://www.amazon.com/s?me=SELLER_IDSie können diese URL finden, indem Sie das Schaufenster des Verkäufers auf Amazon besuchen.
b. Produktauflistungen abrufen
Mit der ID oder URL des Verkäufers können Sie beginnen, die Produktlisten abzurufen. Da die Amazon-Seiten oft paginiert sind, müssen Sie die Paginierung so handhaben, dass alle Produkte erfasst werden.
Anfragen importieren
von bs4 importieren BeautifulSoup
seller_url = "https://www.amazon.com/s?me=SELLER_ID"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, wie Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
def get_products(seller_url):
products = []
while seller_url:
response = requests.get(seller_url, headers=headers)
soup = BeautifulSoup(response.content, "html.parser")
# Extrahieren der Produktdaten
for product in soup.select(".s-title-instructions-style"):
title = product.get_text(strip=True)
produkte.append(titel)
# Ermitteln der URL der nächsten Seite
nächste_seite = soup.select_one("li.a-last a")
seller_url = f "https://www.amazon.com{next_page['href']}" if next_page else None
Produkte zurückgeben
produkte = get_products(verkäufer_url)
print(produkte)4. Handhabung der Paginierung
Amazon-Produktseiten sind oft paginiert und erfordern eine Schleife, die jede Seite durchläuft. Die Logik dafür ist in der Datei get_products Funktion, die das Vorhandensein einer Schaltfläche "Weiter" prüft und die URL der Folgeseite extrahiert.
5. Umgang mit dynamischen Inhalten
Einige Produktdetails, wie z. B. Preis oder Verfügbarkeit, werden möglicherweise dynamisch mit JavaScript geladen. In solchen Fällen müssen Sie Selen oder eine kopfloser Browser wie Dramatiker um die Seite vor dem Scraping zu rendern.
Verwendung von Selenium für dynamische Inhalte
von selenium import webdriver
von selenium.webdriver.chrome.service importieren Dienst
von selenium.webdriver.chrome.options importieren Optionen
von bs4 importieren BeautifulSoup
# Setup Chrome Optionen
chrome_options = Optionen()
chrome_options.add_argument("--headless") # Ausführung im Headless-Modus
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
# Chrome-Treiber starten
service = Dienst('/pfad/zu/chromedriver')
driver = webdriver.Chrome(service=service, options=chrome_options)
# Öffnen Sie die Seite des Verkäufers
driver.get("https://www.amazon.com/s?me=SELLER_ID")
# Warten Sie, bis die Seite vollständig geladen ist
driver.implicitly_wait(5)
# Parsen der Seitenquelle mit BeautifulSoup
soup = BeautifulSoup(driver.page_source, "html.parser")
# Extrahieren der Produktdaten
for product in soup.select(".s-title-instructions-style"):
title = product.get_text(strip=True)
print(Titel)
driver.quit()6. Umgang mit CAPTCHAs
Amazon kann CAPTCHAs präsentieren, um Scraping-Versuche zu verhindern. Wenn Sie auf ein CAPTCHA stoßen, müssen Sie es entweder manuell lösen oder einen Dienst wie 2Captcha um den Prozess zu automatisieren.
Beispiel für die Verwendung von 2Captcha
Einfuhrgesuche
captcha_solution = solve_captcha("captcha_image_url") # Verwenden Sie einen CAPTCHA-Lösungsdienst wie 2Captcha
# Senden Sie die Lösung mit Ihrer Anfrage
Daten = {
field-keywords': 'Ihr_Suchbegriff',
'captcha': captcha_solution
}
response = requests.post("https://www.amazon.com/s", data=data, headers=headers)7. Verwaltung der Vollmacht
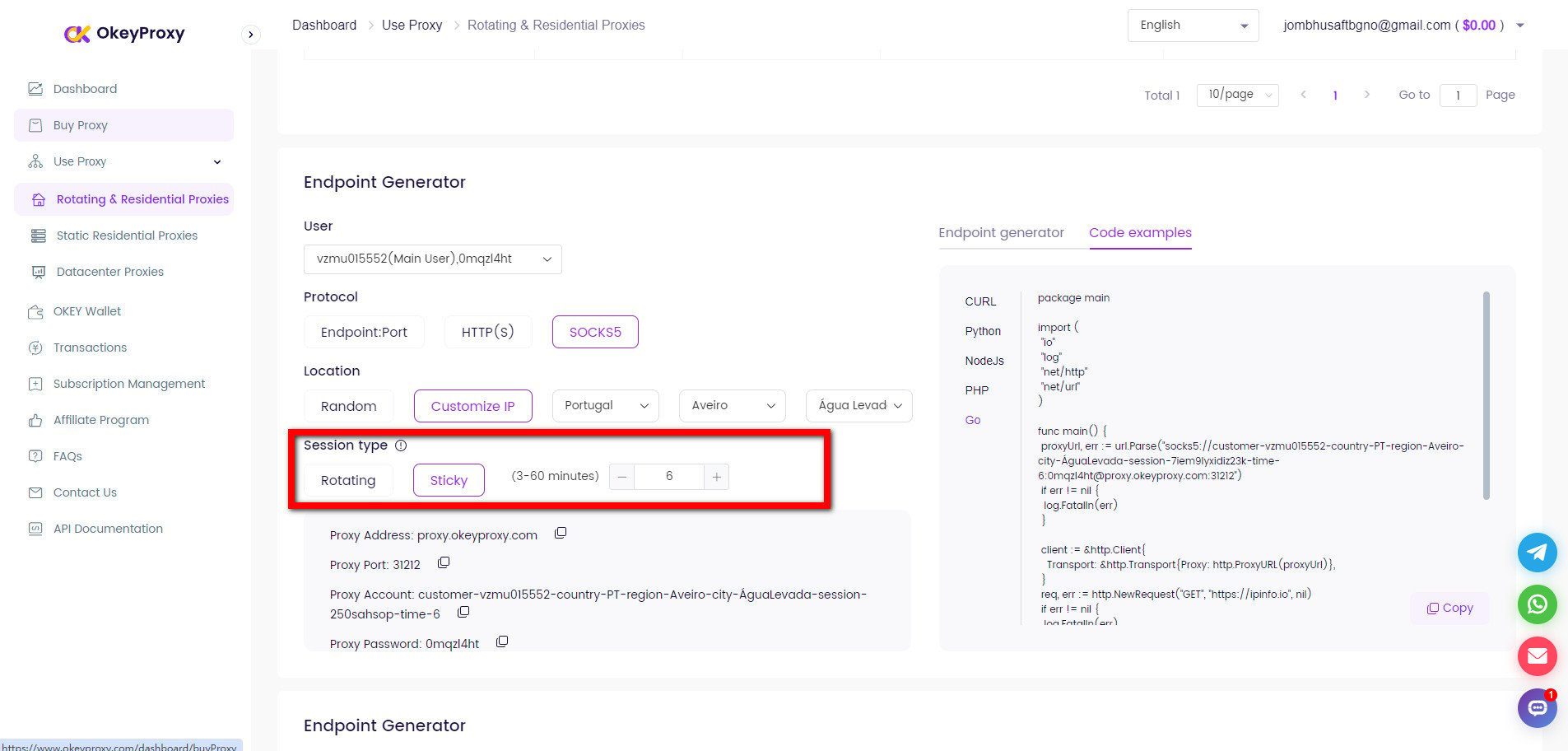
Scraping a seller’s products on Amazon is a common use case for proxies, especially for businesses engaged in price intelligence, competitor monitoring, or product research. Since Amazon employs strong anti-bot measures, proxies for data scraping are essential to bypass detection from Amazon.
Um eine IP-Sperre zu vermeiden, ist es wichtig, rotierende Proxys zu verwenden. Dies kann mit einem Proxy-Management-Tool oder -Dienst erreicht werden.
Einrichten von Proxies mit Abfragen
proxies = {
"http": "http://username:password@proxy_server:port",
"https": "https://username:password@proxy_server:port",
}
response = requests.get(seller_url, headers=headers, proxies=proxies)IP-Adresse rotieren mit OkeyProxy
OkeyProxy ist ein idealer Proxy-Anbieter, der durch eine patentierte Technologie unterstützt wird, die mehr als 150 Millionen echte und konforme rotierende Wohn-IPs zur Verfügung stellt, die eine schnelle Verbindung zu Ziel-Websites in jedem Land/jeder Region ermöglichen und IP-Sperren und -Verbote leicht umgehen.
8. Datenspeicherung
Wenn Sie die Daten erfolgreich ausgewertet haben, speichern Sie sie in einem strukturierten Format. Pandas ist dafür ein hervorragendes Instrument.
Speichern in CSV mit Pandas
import pandas as pd
# Angenommen, Produkte ist eine Liste von Wörterbüchern
df = pd.DataFrame(products)
df.to_csv("amazon_products.csv", index=False)9. Bewährte Praktiken und Herausforderungen
- Respekt robots.txt: Halten Sie sich immer an die Richtlinien, die in Amazons
robots.txtDatei. - Ratenbegrenzung: Implementieren Sie Strategien zur Ratenbegrenzung, um eine Überlastung von Amazons Servern zu verhindern.
- Fehlerbehandlung: Seien Sie darauf vorbereitet, mit verschiedenen Fehlern umzugehen, einschließlich Zeitüberschreitungen bei Anfragen, CAPTCHAs und Fehlern bei nicht gefundenen Seiten.
- Prüfung: Testen Sie Ihren Abstreifer gründlich in einer kontrollierten Umgebung, bevor Sie ihn in großem Maßstab einsetzen.
- Rechtmäßigkeit: Vergewissern Sie sich, dass Ihre Scraping-Aktivitäten im Einklang mit den gesetzlichen Bestimmungen und den Nutzungsbedingungen von Amazon stehen.
10. Skalierung des Scraping-Prozesses
Für groß angelegte Scraping-Operationen sollten Sie die Verwendung eines Frameworks wie Scrapy oder die Bereitstellung Ihres Scrapers auf einer Cloud-Plattform mit verteilten Crawling-Funktionen.
Andere Methode für Scraping Amazon Verkäufer Produkte
Amazon bietet APIs wie die Product Advertising API für den Zugriff auf Produktinformationen. Obwohl diese Methode legitim ist und von Amazon unterstützt wird, erfordert sie eine Genehmigung für den API-Zugang und ist in ihrem Umfang begrenzt.
-
Vorteile:
Offiziell unterstützt, zuverlässig.
-
Nachteile:
Begrenzter Zugang, erfordert eine Genehmigung und kann mit Nutzungskosten verbunden sein.
FAQs about Scraping Data from Amazon
F1: Ist es legal, Amazon nach Produktdaten zu durchsuchen?
A: Das Scraping von Amazon ohne Erlaubnis kann gegen die Nutzungsbedingungen verstoßen und zu rechtlichen Konsequenzen oder zur Sperrung von IP-Adressen führen. Konsultieren Sie immer einen Rechtsbeistand, bevor Sie fortfahren.
F2: Wie kann man vermeiden, beim Scrapen von Amazon blockiert zu werden?
A: Die Verwendung von Proxys zur Rotation der IP, die Einhaltung von robots.txt, die Einführung von Verzögerungen zwischen den Anfragen, die Vermeidung von zu häufigem Scraping usw. sind einige Maßnahmen, die das Risiko, von Amazon blockiert zu werden, minimieren können.
F3: Warum funktioniert mein Scraping-Skript nicht mehr?
A: Überprüfen Sie, ob Amazon seine Website-Struktur geändert oder neue Anti-Scraping-Maßnahmen eingeführt hat, und passen Sie das Skript an, um etwaige Änderungen zu berücksichtigen. Überprüfen und pflegen Sie das Skript außerdem regelmäßig, um die kontinuierliche Funktionalität zu gewährleisten.
Zusammenfassung
Das Scraping der Produkte eines Verkäufers auf Amazon beinhaltet die Identifizierung der eindeutigen URL des Verkäufers, das Navigieren durch paginierte Produktlisten und die Handhabung dynamischer Inhalte mit Tools wie Selenium. Aufgrund der Anti-Scraping-Maßnahmen von Amazon, wie CAPTCHAs und Ratenbegrenzungen, ist es wichtig, Folgendes zu verwenden Drehbevollmächtigte und beachten Sie die Einhaltung ihrer Nutzungsbedingungen. Die Verwendung von Bibliotheken wie BeautifulSoup für statische Inhalte und Selenium für dynamische Inhalte sowie die sorgfältige Verwaltung von IP-Adressen und Ratenbeschränkungen können dazu beitragen, Produktdaten effizient zu extrahieren und zu speichern und gleichzeitig das Risiko einer Blockierung zu minimieren.








