I dati sono la pietra miliare dell'analisi della concorrenza, delle ricerche di mercato e della strategia aziendale. Una delle fonti di dati più preziose per le aziende di e-commerce è Amazon, il più grande mercato online del mondo. Lo scraping dei prodotti di un venditore su Amazon può fornire informazioni sulle strategie di prezzo, sull'offerta di prodotti e sulle recensioni dei clienti, fondamentali per prendere decisioni aziendali informate.
Questo articolo approfondisce il processo di scraping dei prodotti di un venditore su Amazon, illustrando gli strumenti essenziali, le tecniche e le best practice e affrontando al contempo considerazioni legali ed etiche.
La struttura dei dati di Amazon include?
Il sito web di Amazon è strutturato in modo da classificare i prodotti, le recensioni, i prezzi e altri dettagli. Per effettuare lo scraping dei dati dei prodotti in modo efficace, è fondamentale comprendere i seguenti componenti:
- Annunci di prodotti: Contiene dettagli come il nome del prodotto, la descrizione, il prezzo e le immagini.
- Informazioni sul venditore: Include le valutazioni del venditore, il numero di prodotti e il nome del venditore.
- Recensioni e valutazioni: Fornisce il feedback dei clienti e le valutazioni dei prodotti.
- Categorie di prodotti: Aiuta a filtrare e organizzare i prodotti.
Raschiare i prodotti di un venditore su Amazon passo dopo passo
Lo scraping dei prodotti di un venditore su Amazon richiede un approccio dettagliato e strutturato, soprattutto a causa delle sofisticate misure anti-scraping di Amazon. Qui di seguito trovate un tutorial completo che copre vari aspetti del processo, dall'impostazione dell'ambiente alla gestione di sfide come i CAPTCHA e i contenuti dinamici.
1. Preparazione del Web Scraping
Prima di immergersi nel processo di scraping, assicurarsi che il proprio ambiente sia configurato con gli strumenti e le librerie necessarie.
a. Strumenti e biblioteche
- Pitone: Preferito per il suo ricco ecosistema di biblioteche.
- Biblioteche:
richieste: Per effettuare richieste HTTP.Bella Zuppa: Per analizzare il contenuto HTML.Selenio: Per gestire i contenuti e le interazioni dinamiche.Panda: Per la manipolazione e l'archiviazione dei dati.Scarti: Se preferite un approccio di scraping più scalabile e basato su spider.
- Gestione delle deleghe:
richieste-ip-rotatore: Una libreria per la rotazione degli indirizzi IP.- Servizi proxy come
OkeyProxyper i proxy rotanti.
- Risolutori di CAPTCHA:
- Servizi come
2CaptchaoAnti-Captchaper risolvere i CAPTCHA.
- Servizi come
b. Impostazione dell'ambiente
- Installare Pitone (se non è già installato).
- Impostare un ambiente virtuale:
python3 -m venv amazon-scraper sorgente amazon-scraper/bin/activate - Installare le librerie necessarie:
pip installa richieste beautifulsoup4 selenium pandas scrapy
2. Comprendere i meccanismi anti-scraping di Amazon
Amazon impiega diverse tecniche per impedire lo scraping automatico, che rappresenta una sfida per la raccolta dei dati:
- Limitazione della velocità: Amazon limita il numero di richieste che è possibile effettuare in un breve periodo.
- Blocco IP: Richieste frequenti da un singolo IP possono portare a divieti temporanei o permanenti.
- CAPTCHA: Questi vengono presentati per verificare se l'utente è umano.
- Contenuti basati su JavaScript: Alcuni contenuti sono caricati dinamicamente con JavaScript, che richiede una gestione speciale.
3. Individuazione dei prodotti del venditore
a. Identificare l'ID del venditore
Per scrapare i prodotti di un venditore specifico, è necessario innanzitutto identificare l'ID univoco del venditore o l'URL della sua vetrina. L'URL di solito segue questo formato:
https://www.amazon.com/s?me=SELLER_IDÈ possibile trovare questo URL visitando la vetrina del venditore su Amazon.
b. Recuperare gli elenchi dei prodotti
Con l'ID o l'URL del venditore, è possibile iniziare a recuperare gli elenchi dei prodotti. Poiché le pagine di Amazon sono spesso impaginate, è necessario gestire la paginazione per garantire lo scraping di tutti i prodotti.
importare le richieste
da bs4 importa BeautifulSoup
seller_url = "https://www.amazon.com/s?me=SELLER_ID"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, come Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
def get_products(seller_url):
prodotti = []
while seller_url:
response = requests.get(seller_url, headers=intestazioni)
soup = BeautifulSoup(response.content, "html.parser")
# Estrarre i dettagli del prodotto
per prodotto in soup.select(".s-title-instructions-style"):
title = product.get_text(strip=True)
products.append(title)
# Trovare l'URL della pagina successiva
next_page = soup.select_one("li.a-last a")
seller_url = f "https://www.amazon.com{next_page['href']}" if next_page else None
restituire i prodotti
prodotti = get_products(seller_url)
print(prodotti)4. Gestione della paginazione
Le pagine dei prodotti Amazon sono spesso paginate e richiedono un ciclo per passare attraverso ogni pagina. La logica per questo è inclusa nel file get_products in cui controlla la presenza di un pulsante "Avanti" ed estrae l'URL della pagina successiva.
5. Gestione dei contenuti dinamici
Alcuni dettagli del prodotto, come il prezzo o la disponibilità, possono essere caricati dinamicamente tramite JavaScript. In questi casi, è necessario utilizzare il metodo Selenio o un browser senza testa come Drammaturgo per rendere la pagina prima dello scraping.
Usare Selenium per i contenuti dinamici
da selenium import webdriver
da selenium.webdriver.chrome.service import Service
da selenium.webdriver.chrome.options importare Options
da bs4 import BeautifulSoup
# Configurare le opzioni di Chrome
chrome_options = Opzioni()
chrome_options.add_argument("--headless") # Eseguire in modalità headless
chrome_options.add_argument("--no-sandbox")
chrome_options.add_argument("--disable-dev-shm-usage")
# Avviare il driver di Chrome
service = Service('/path/to/chromedriver')
driver = webdriver.Chrome(service=service, options=chrome_options)
# Aprire la pagina del venditore
driver.get("https://www.amazon.com/s?me=SELLER_ID")
# Attendere che la pagina venga caricata completamente
driver.implicitly_wait(5)
# Analizzare il sorgente della pagina con BeautifulSoup
soup = BeautifulSoup(driver.page_source, "html.parser")
# Estrarre i dettagli del prodotto
per prodotto in soup.select(".s-title-instructions-style"):
title = product.get_text(strip=True)
print(titolo)
driver.quit()6. Gestire i CAPTCHA
Amazon può presentare CAPTCHA per bloccare i tentativi di scraping. Se si incontra un CAPTCHA, è necessario risolverlo manualmente o utilizzare un servizio come 2Captcha per automatizzare il processo.
Esempio di utilizzo di 2Captcha
richieste di importazione
captcha_solution = solve_captcha("captcha_image_url") # Utilizzare un servizio di risoluzione CAPTCHA come 2Captcha
# Inviare la soluzione con la richiesta
dati = {
field-keywords': 'your_search_term',
captcha': captcha_solution
}
response = requests.post("https://www.amazon.com/s", data=data, headers=headers)7. Gestione delle deleghe
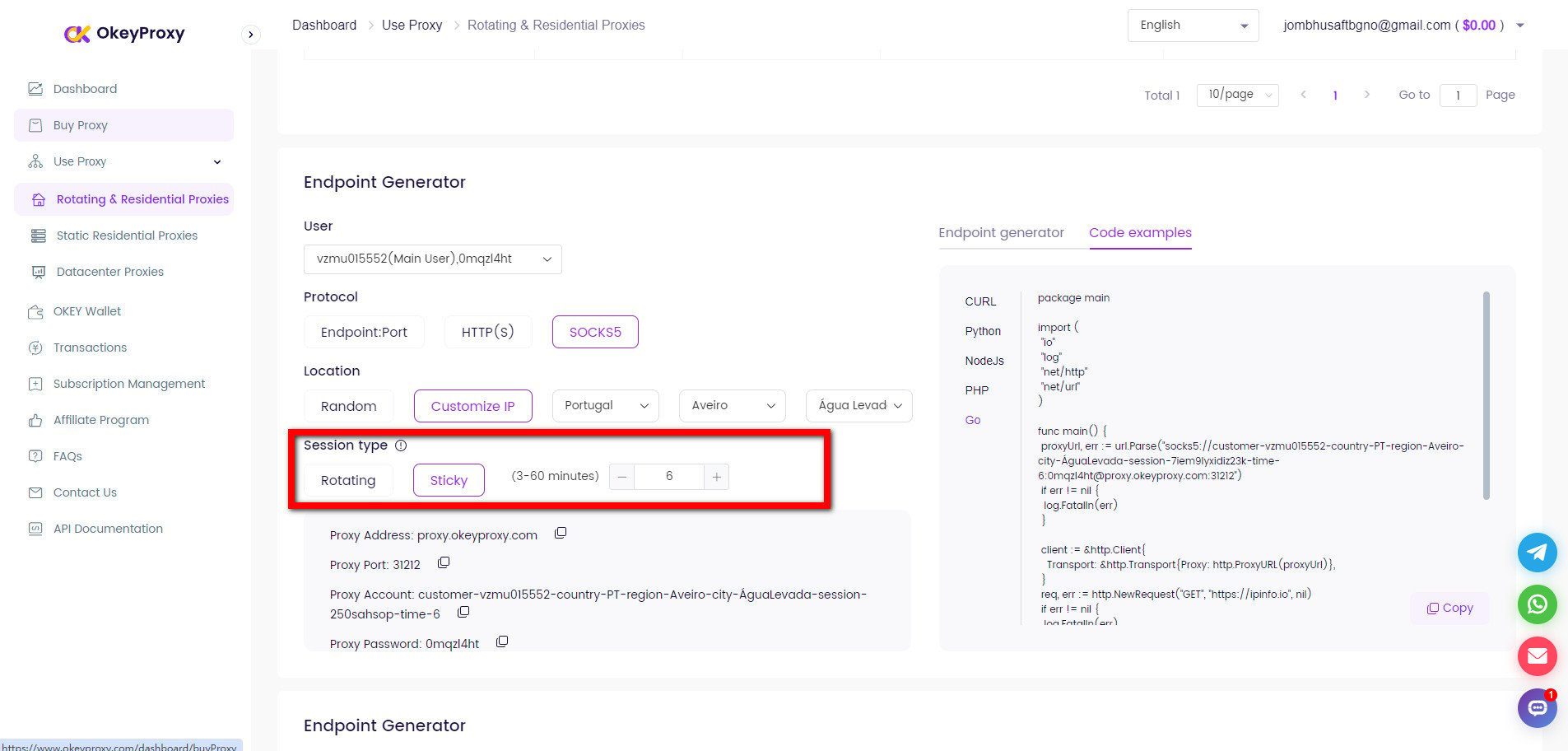
Per evitare il blocco degli IP, è fondamentale utilizzare proxy a rotazione. Questo può essere ottenuto utilizzando uno strumento o un servizio di gestione dei proxy.
Impostazione dei proxy con le richieste
proxy = {
"http": "http://username:password@proxy_server:port",
"https": "https://username:password@proxy_server:port",
}
response = requests.get(seller_url, headers=intestazioni, proxies=proxies)Ruotare l'indirizzo IP con OkeyProxy
OkeyProxy è un provider proxy ideale supportato da una tecnologia brevettata, che fornisce oltre 150 milioni di IP residenziali a rotazione reali e conformi, che consentono di connettersi rapidamente ai siti web di destinazione in qualsiasi paese/regione e di aggirare facilmente i blocchi e i divieti degli IP.
8. Memorizzazione dei dati
Una volta effettuato lo scraping dei dati, memorizzateli in un formato strutturato. Panda è uno strumento eccellente per questo scopo.
Salvare in CSV con Pandas
importare pandas come pd
# Assumendo che i prodotti siano un elenco di dizionari
df = pd.DataFrame(products)
df.to_csv("amazon_products.csv", index=False)9. Migliori pratiche e sfide
- Rispetto robots.txt: Rispettare sempre le linee guida specificate nel sito di Amazon.
robots.txtfile. - Limitazione della velocità: Implementare strategie di limitazione della velocità per evitare di sovraccaricare i server di Amazon.
- Gestione degli errori: Preparatevi a gestire vari errori, tra cui timeout della richiesta, CAPTCHA ed errori di pagina non trovata.
- Test: Testate accuratamente il vostro raschiatore in un ambiente controllato prima di utilizzarlo in scala.
- Legalità: Assicuratevi che le vostre attività di scraping siano conformi alle normative legali e ai termini di servizio di Amazon.
10. Scalare il processo di scraping
Per le operazioni di scraping su larga scala, si consiglia di utilizzare un framework come Scarti o di distribuire lo scraper su una piattaforma cloud con funzionalità di crawling distribuito.
Altri metodi per lo scraping dei prodotti dei venditori Amazon
Amazon fornisce API come l'API Product Advertising per accedere alle informazioni sui prodotti. Sebbene questo metodo sia legittimo e supportato da Amazon, richiede l'approvazione dell'accesso alle API e ha una portata limitata.
-
Pro:
Supportato ufficialmente, affidabile.
-
Contro:
Accesso limitato, richiede l'approvazione e può comportare costi di utilizzo.
Domande frequenti su Scrape Data da Amazon
D1: È legale effettuare lo scraping di Amazon per ottenere dati sui prodotti?
R: Lo scraping di Amazon senza autorizzazione può violare i loro termini di servizio e potrebbe comportare conseguenze legali o il blocco degli indirizzi IP. Consultare sempre un consulente legale prima di procedere.
D2: Come evitare di essere bloccati durante lo scraping di Amazon?
R: L'uso di proxy per ruotare l'IP, il rispetto di robots.txt, l'implementazione di ritardi tra le richieste, l'evitare lo scraping troppo frequente, ecc. sono alcune misure che potrebbero ridurre al minimo il rischio di essere bloccati da Amazon.
D3: Perché il mio script di scraping smette di funzionare?
R: Verificate se Amazon ha modificato la struttura del suo sito web o ha implementato nuove misure anti-scraping e regolate lo script per adattarlo a eventuali modifiche. Inoltre, controllate e mantenete regolarmente lo script per garantirne la funzionalità.
Sintesi
Lo scraping dei prodotti di un venditore su Amazon comporta l'identificazione dell'URL univoco del venditore, la navigazione tra gli elenchi di prodotti impaginati e la gestione di contenuti dinamici con strumenti come Selenium. A causa delle misure anti-scraping di Amazon, come i CAPTCHA e la limitazione della velocità, è essenziale usare proxy rotanti e considerare la conformità ai loro termini di servizio. L'uso di librerie come BeautifulSoup per i contenuti statici e Selenium per i contenuti dinamici, insieme a un'attenta gestione degli indirizzi IP e dei limiti di velocità, può aiutare a estrarre e archiviare in modo efficiente i dati dei prodotti, riducendo al minimo il rischio di essere bloccati.